Objectives
Key Features
Machine learning and analytics in complex systems frequently require the addition of external data sets to generate new insights. These data sets are often unstructured, with a large amount of columns, and sensitive data might be hidden in poorly described columns.
Today, to integrate these unstructured files, a data engineer requires many tools and significant effort to understand the data, perform QA and load the data into a central repository. These tools are expensive and feature rich, where data transformation and analysis is included but often with a narrow focus.
Also, if the files contain sensitive information, the environment might require specific security considerations. In Canada, PIPEDA (the Personal Information Protection and Electronic Documents Act) requires corporations to put safeguards around the handling of any personal information.
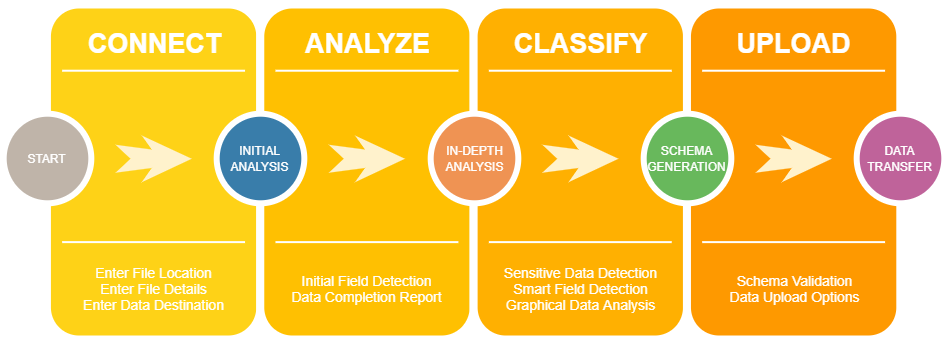
Existing ETL tools require significant effort to create packages – even for simple files -and end up being a bottleneck in any data exploration or science project. This solution provides a simple 4-step workflow covering the most common tasks.
Technical Benefits
In addition to the application features, this solution can be used as a template to integrate with the following technologies:
- .NET Core 3 on Linux
- Docker deployment with .NET Core
- Blazor web pages for building rich interactive UIs using C# instead of JavaScript
- Electron.NET for packaging web pages as standalone application
- Visual Studio Solution with common code for Docker and Electron packages
Scalable & Portable Design
The code base is designed for portability across multiple OSes (Linux, Windows, MacOS) and hosts (Docker, Electron). The underlying architecture follows patterns that enable the efficient handling of large data sets.
The API is extensible and other analyzers can be added to identify new data types.
Application Workflow
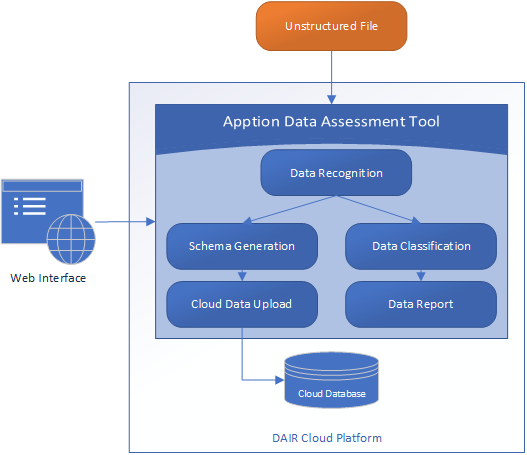
The diagram below illustrates the structure of the solution.