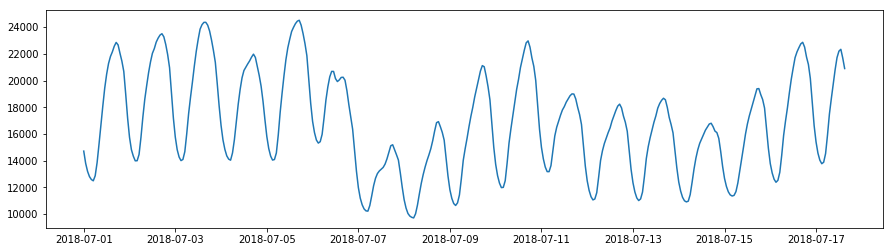
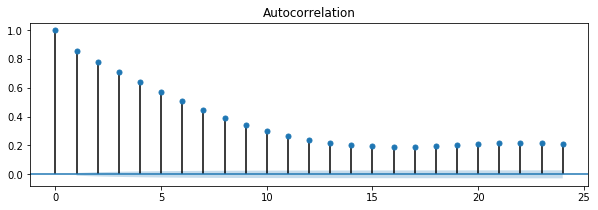
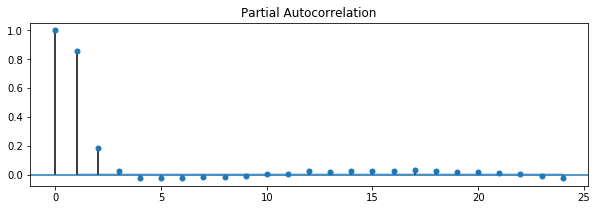
After January 17, 2025:
- Screenshots should remain accurate, however where you are instructed to login to your DAIR account in AWS, you will be required to login to a personal AWS account.
- Links to AWS CloudFormation scripts for the automated deployment of each sample application should remain intact and functional.
- Links to GitHub repositories for downloading BoosterPack source code will remain valid as they are owned and sustained by the BoosterPack Builder (original creators of the open-source sample applications).