La Solution type du propulseur « Classification et recherche automatiques de documents » illustre comment FormKiQ utilise Micronaut, Apache Kafka, Tesseract (moteur de reconnaissance optique de caractères), Elasticsearch et le traitement du langage naturel (TLN) pour catégoriser et étiqueter automatiquement des documents en fonction de leur contenu, et ainsi pouvoir les retrouver et les récupérer rapidement.
Énoncé du problème
Beaucoup d’organisations trouveraient utile de récupérer des documents précis, conservés dans un dépôt, tout en glanant plus d’informations de manière à pouvoir trouver et grouper certaines données. À l’heure actuelle, on y parvient en effectuant une recherche manuelle ou en saisissant à la main les métadonnées du document, deux méthodes onéreuses, inefficaces et laborieuses. C’est pourquoi nous en avons conçu une meilleure!
Classer et retrouver automatiquement des documents apporterait beaucoup à certaines industries. Les cabinets d’avocats et les services juridiques, par exemple, pourraient examiner les demandes de documents et y répondre, de même qu’accomplir d’autres tâches dans le même domaine. Le temps manque souvent pour satisfaire pareilles requêtes et les coûts que cela entraîne sont parfois exorbitants. Pourraient aussi bénéficier de cette technologie les services professionnels dans certains domaines comme le génie et la construction, où chaque service doit impérativement suivre le cheminement de la documentation, et où une erreur humaine ou le moindre retard s’avère coûteux, en empêchant l’organisation de remplir ses obligations contractuelles.
Les coûts élevés et les délais n’auront pas seulement un impact sur la vitalité financière de l’organisation. Dans certains cas (dans l’industrie médicale, par exemple), leurs répercussions pourraient affecter la population elle-même.
Les solutions classiques reposent sur la normalisation des procédures opérationnelles et des flux de tâches comportant maintes étapes manuelles. En plus d’être laborieux, les procédés de ce genre consomment toutefois énormément de ressources et leur précision laisse à désirer en raison des erreurs humaines et des incohérences dans la classification.
En recourant à la reconnaissance optique des caractères (ROC), au traitement du langage naturel (TLN) et à la recherche plein texte, la Solution type automatise la création de métadonnées sur les documents, économise du temps, atténue les risques d’erreur et allège les coûts, de manière générale.
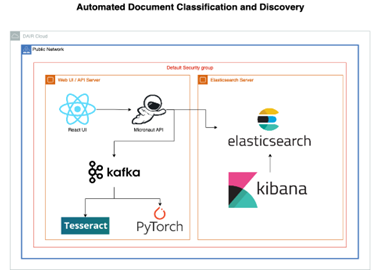
Classification et recherche automatiques de documents dans le Nuage de l’ATIR – Solution type
Diagramme de la Solution type
Le diagramme ci-dessous illustre la structure de la Solution type.
Description des éléments
Voici un aperçu des principaux éléments qui composent la Solution type.
Élément
Description
Application React UI
Interface utilisateur web permettant d’interagir avec l’application
Kafka
Plateforme répartie de diffusion en continu employée pour coordonner le traitement des documents tout au long des différentes étapes du flux de tâches
Micronaut Framework
Cadriciel web fondé sur une machine virtuelle Java qui traite les demandes de l’API, reçoit les messages de Kafka et y donne suite, de même que rédige les documents pour le serveur Elasticsearch
Tesseract
Moteur de reconnaissance optique de caractères (ROC) de source ouverte abondamment utilisé pour identifier le texte dans les images numériques
PyTorch
Cadriciel d’apprentissage automatique de source ouverte principalement utilisé pour créer et entraîner les réseaux de neurones profonds. Le but est d’obtenir une plateforme assez souple et conviviale dont le développeur pourra se servir pour bâtir des modèles complexes qui accompliront diverses tâches comme la reconnaissance d’images, le TLN et le reste
Elasticsearch
Moteur de recherche et d’analyse de source ouverte conçu pour stocker, chercher et analyser en temps réel des données volumineuses, structurées ou pas. Permet à l’utilisateur d’effectuer aisément des recherches complexes et d’analyser ses données
Déploiement et configuration
Pour déployer la Solution type, les participants de l’ATIR n’ont qu’à se rendre à la partie « Classification et recherche automatiques de documents » sur la page du Catalogue des Propulseurs de l’ATIR et suivre les instructions afin d’en créer une nouvelle instance.
Avant de déployer l’application, on présume que vous aurez effectué ce qui suit :
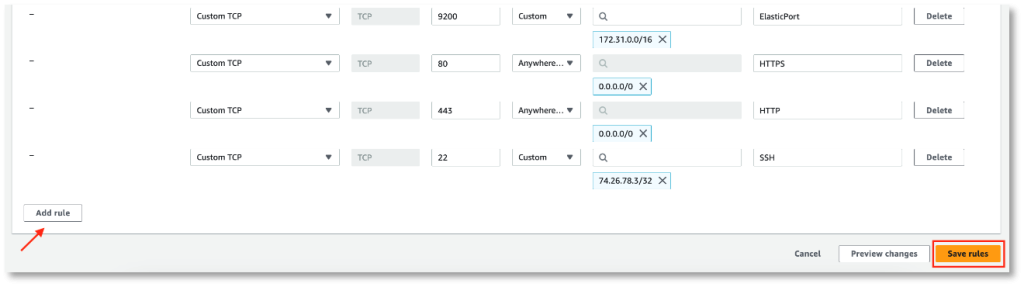
créé une règle pour les groupes de sécurité autorisant les sources extérieures (0.0.0.0/0) à se connecter aux machines virtuelles (MV) engendrées dans l’ATIR par les ports 80 (HTTP) et 443 (HTTPS);
créé une règle pour les groupes de sécurité autorisant le réseau VPC par défaut (172.31.0.0/16) à se connecter au port 9200 de l’API Elasticsearch;
créé un groupe de sécurité vous autorisant à vous connecter par SSH (port 22) aux MV du Nuage de l’ATIR établies à partir de l’adresse IP que vous utilisez;
créé votre clé SSH privée donnant accès aux MV du Propulseur de l’ATIR;
Déploiement de la Solution type « Classification et recherche automatiques de documents » dans le Nuage de l’ATIR
Prêt à décoller?
Ouvrez une séance sur votre compte AWS de l’ATIR en suivant les instructions que vous a fournies l’équipe de l’ATIR.
Cliquez DÉPLOYER pour lancer le Propulseur avec une pile de la console CloudFormation d’AWS.
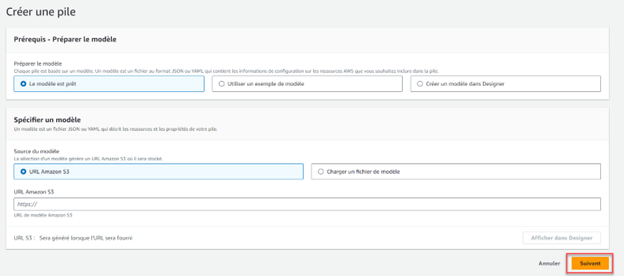
Remplissez le formulaire de configuration
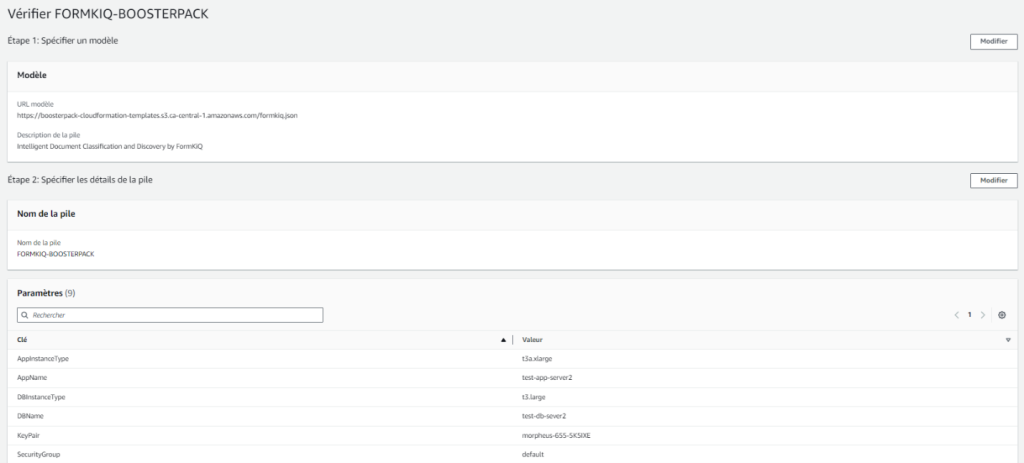
Cliquez Suivant pour passer à la deuxième étape et remplissez le formulaire. Dans les champs AppName et DBName, donnez un nom unique à l’instance des serveurs de l’application web et de la base de données, respectivement.
Configurez aussi le mot de passe et l’identifiant de l’application web en remplissant respectivement les champs WebPassword et WebUsername. Complétez le reste du formulaire avec les choix du menu déroulant. Veuillez noter que certains paramètres (comme « ServerImage », « AppInstanceType » ou « DBInstanceType ») sont préconfigurés et ne peuvent être modifiés.
Remarque : Choisissez des paramètres sûrs pour WebUserName et WebPassword.
Cliquez SUIVANT pour passer à la troisième étape de CloudFormation. Cette partie concerne la configuration d’options avancées ou supplémentaires inutiles dans le cas qui nous intéresse. Cliquez simplement « Suivant » au bas de la page pour sauter cette étape et passer à la quatrième et dernière de CloudFormation.
La dernière partie vous permet de vérifier la configuration actuelle du Propulseur et d’y apporter des modifications avec le bouton « Modifier », si vous le désirez. Une fois que la configuration vous convient, cliquez « Soumettre », au bas de la page, pour déployer le Propulseur.
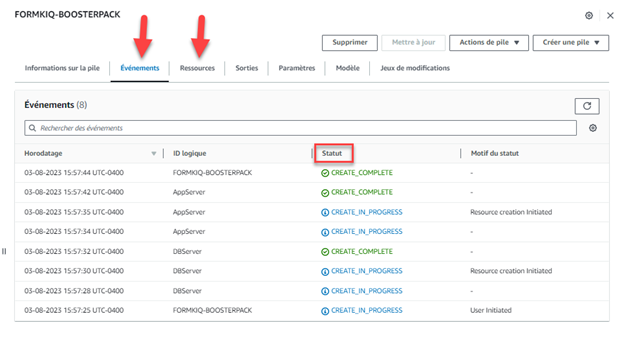
Le déploiement commence par la création de deux (2) nouvelles instances (celles du serveur de l’application web et celle du serveur de la base de données). Le reste est automatique. Suivre le développement des instances AWS n’est possible qu’avec les onglets « Événements » et « Ressources » de la console CloudFormation. Pour vérifier l’avancement du déploiement, vous devrez donc vous connecter aux serveurs de l’application web et de la base de données.
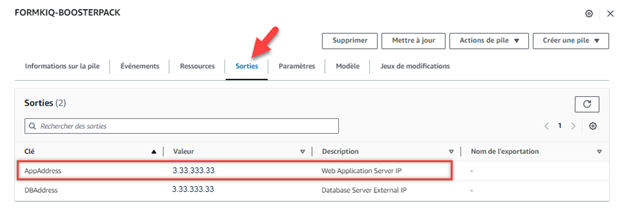
Notez la valeur « Web Application Server IP » qui apparaît sur l’onglet « Sorties » de la page CloudFormation du Propulseur. Il s’agit de l’adresse IP externe (publique) du serveur de l’application web créé par le Propulseur. Vous en aurez besoin pour accéder à l’interface web de l’application ou vous connecter au serveur par le protocole SSH.
Connectez-vous au serveur de l’application à partir d’une coquille ou d’un terminal utilisant le protocole SSH avec la commande suivante :
ssh -i key_file.pem ec2-user@IP
Remplacez « key_file » par la clé privée de la biclé SSH choisie dans les paramètres de configuration de CloudFormation et remplacez « IP » par la valeur de l’onglet Sorties notée précédemment.
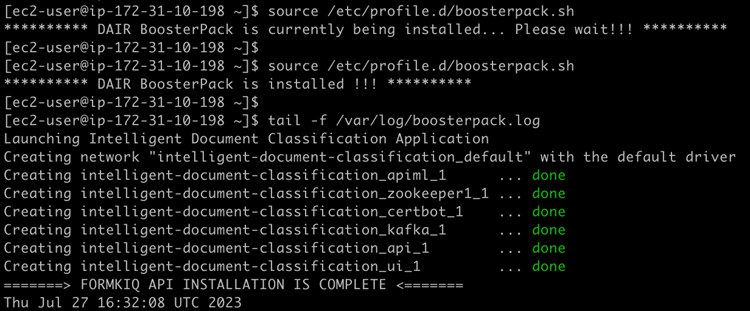
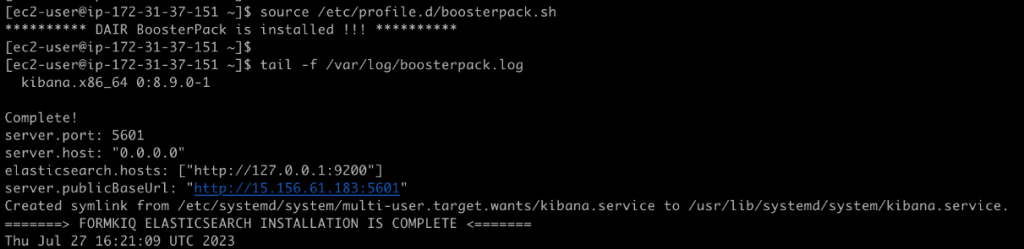
Une fois la connexion avec le serveur de l’application établie, vous pourrez suivre le déploiement du script d’automatisation avec les commandes que voici :
source /etc/profile.d/boosterpack.sh
tail -f /var/log/boosterpack.log
Reprenez les mêmes étapes pour suivre le déploiement du serveur de la base de données (habituellement il est plus rapide que celui du serveur de l’application web).
Le déploiement du Propulseur (application web et base de données) dure jusqu’à quinze (15) minutes.
Configuration et lancement de l’application
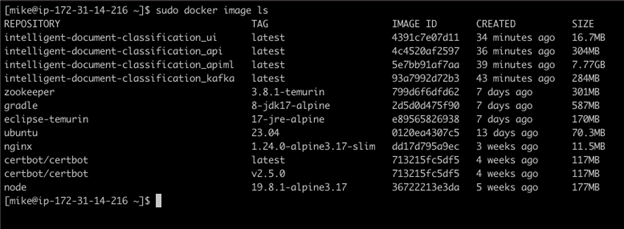
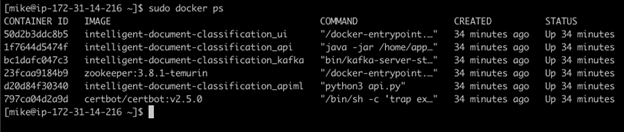
L’application démarre automatiquement après l’instanciation. Pour s’assurer qu’il y a exécution, utilisez la commande Docker ci-dessous dans l’invite de commande.
sudo docker image ls
sudo docker ps
L’interface utilisateur est accessible par le navigateur grâce à un URL sécurisé incluant l’adresse IP du serveur de l’application web (AppAddress), précédemment extraite de l’onglet Sorties de la console CloudFormation.
https://app.<AppAddress>.nip.io
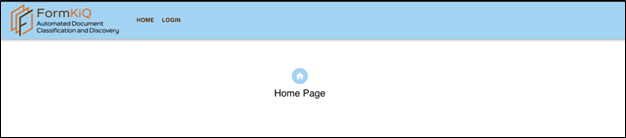
La page d’accueil de l’application (illustration ci-dessous) devrait s’afficher à l’écran quand vous saisissez l’URL.
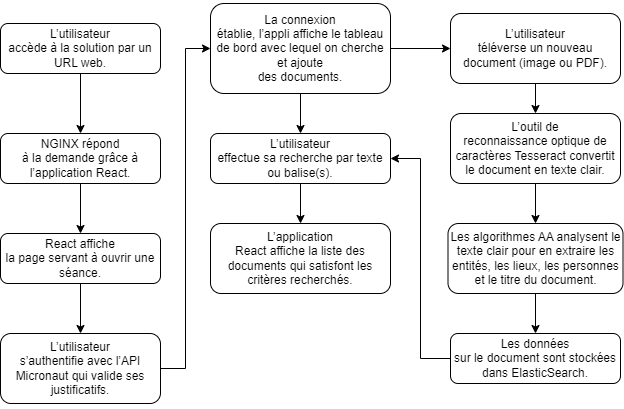
Démonstration de la technologie
Cette partie montre comment fonctionne le Propulseur « Classification et recherche automatiques de documents ».Son utilité réside dans la création automatique de métadonnées/étiquettes pour les documents. Il en améliore donc la catégorisation et la récupération.
La démonstration vous apprendra ce qui suit.
Comment téléverser un nouveau document
Comment le convertir en texte clair avec le moteur ROC Tesseract
Comment analyser le texte clair avec les algorithmes d’apprentissage automatique (AA) afin d’en extraire les entités, les lieux, les personnes et le titre
Comment stocker le document dans Elasticsearch
Comment retrouver un document avec du texte ou des balises
Ouverture d’une séance
L’application est accessible par navigateur à partir de l’adresse IP externe qui lui a été attribuée (https://app.<AppAddress>.nip.io).
Cliquez Login, puis saisissez l’identifiant (WebUsername) et le mot de passe (WebPassword) que vous avez choisis à la configuration des paramètres de CloudFormation lors du déploiement du Propulseur.
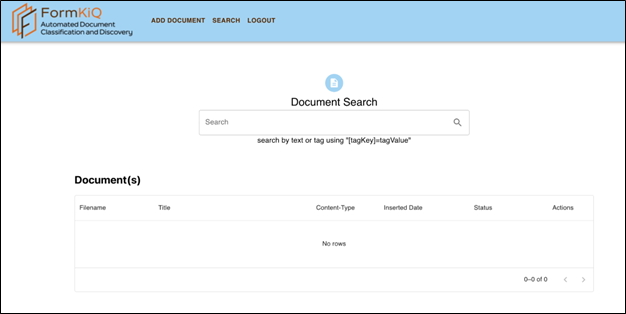
Chercher un document
Une fois la connexion établie, la page « Document Search » (recherche de documents) vous permet de retrouver un document à partir de texte ou de balises.
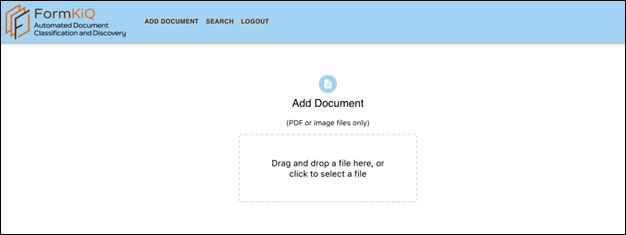
Ajouter un document
La page « Add Document » (ajout de documents) vous permet de téléverser un ou plusieurs documents. Le téléversement terminé, les documents seront convertis en texte clair par reconnaissance optique des caractères, puis les algorithmes d’apprentissage automatique produiront des balises pour les entités et donneront un titre au document.
Conclusion
Supprimez l’instance dans le Nuage de l’ATIR pour arrêter l’application et libérer les ressources qu’elle exploite. Pour cela, revenez à la page Piles de la console CloudFormation et supprimez la pile qui correspond au Propulseur. Plus sur la suppression d’une pile dans Cloudformation.
Facteurs à prendre en considération
Autres possibilités de déploiement
Cette solution se déploie sur une instance installée sur un seul nœud d’Elasticsearch. Pour garantir la disponibilité des solutions plus importantes et rehausser leur performance, il se pourrait qu’on doive installer plusieurs instances dans le Nuage de l’ATIR et créer une grappe (cluster) dans Elasticsearch. Gérer une grappe avec des solutions aussi simples que celle de la Solution type ajouterait une complexité inutile à la chose et engendrerait des frais superflus.
La solution recourt aussi à une seul instance Docker pour gérer l’interface utilisateur, l’API Micronaut et l’API d’apprentissage automatique (AA). L’API AA peut recourir à plusieurs serveurs, selon le nombre de documents traités. L’entreprise pourrait donc vouloir exploiter une deuxième instance de la solution et réserver la première totalement à l’API AA. Dans un tel cas, on devra apporter des modifications mineures à docker-compose-prod.yml afin de configurer le serveur API_AA.
Technologies de rechange
Les technologies et les outils employés par la Solution type viennent de sources ouvertes populaires et ont été choisis parce qu’ils s’intègrent bien ensemble. Néanmoins, il pourrait être remplacés par d’outres outils, exclusifs ou d’utilisation libre, en fonction de la plateforme, des compétences et du soutien souhaité. En voici quelques exemples.
Outil
Exclusif
Utilisation libre
Tesseract OCR
AWS Textract/Google Vision OCR
doctr
Docker
AWS Fargate
Kubernetes
Elasticsearch
Algolia
Typesense
Diffusion continue(solutions de rechange à Kafka)
Azure Event Hubs
RabbitMQ, Amazon MQ, Redis
Couche de présentation (solutions de rechange à React)
s/o
Angular, Vue
Architecture des données
La Solution type stocke les fichiers dans le système de fichiers du serveur et entrepose les métadonnées dans Elasticsearch, ce qui illustre une maîtrise parfaite des principes. Toutefois, un environnement de production sera sans doute mieux servi par un stockage en nuage (comme Amazon S3). Bien qu’Elasticsearch se prête surtout à la recherche plein texte (à l’instar d’Algolia et de Typesense), il est possible qu’une base de données comme PostgreSQL, qui offre aussi une fonctionnalité de recherche plein texte, bien que restreinte, convienne davantage à d’autres applications.
On a simplifié l’accès aux données en le limitant à un seul. Pour les scénarios dans lesquels de nombreux utilisateurs disposent d’un accès de niveau variable aux données, il serait préférable d’exercer un contrôle par rôle ou par attributs.
Sécurité
La Solution type a été conçue aux fins de démonstration. On pourra s’en servir comme cadre de base afin de développer plus rapidement la solution désirée. La Solution type n’a pas été élaborée pour servir dans un environnement de production. Diverses mesures de sécurité et améliorations seront donc requises si on veut l’utiliser dans un environnement de ce genre. Les points qui suivent indiquent ce qu’il faudrait ajouter pour sécuriser la Solution type davantage.
Mot de passe. Nous avons établi un mot de passe par défaut pour plusieurs outils et applications de la Solution type comme Elasticsearch et l’interface utilisateur. Changez toujours ce mot de passe pour un plus sûr.
Pare-feu pour application web (WAF). L’insertion d’un WAF avant l’interface utilisateur et l’API préviendront l’injection de SQL, l’injection de code indirecte (XSS) et la falsification des demandes entre sites (CSRF).
Extensibilité/Disponibilité
La Solution type repose sur une infrastructure de microservices. Pour agrandir une architecture de ce genre, on élargira chaque service et leur infrastructure en fonction de la demande.
Il est possible d’élargir Elasticsearch en créant une grappe (cluster) qui permettra de traiter des données et des demandes volumineuses. Les grappes peuvent être élargies horizontalement comme on le désire par l’addition de nœuds. La grappe gagne en performance et en fiabilité en grossissant.
Les API peuvent aussi être élargies par la création d’une grappe NGINX, conçue pour prendre en charge un trafic important et pour rehausser la performance de l’application web. La grappe de serveurs NGINX permettra de répartir les demandes entre divers serveurs, d’alléger la charge qui s’exerce sur chacun d’eux et d’améliorer de manière générale la performance du système.
API
La Solution type comprend une API dont le point terminal est accessible publiquement. Par conséquent, il est essentiel de procéder à une authentification quelconque. La Solution type utilise des jetons JWT pour cela, une façon sûre et normalisée pour les deux parties d’authentifier les demandes et d’échanger de l’information.
Coût
Un avantage de la Solution type est que les outils et les technologies qu’elle intègre sont tous de source ouverte. Il n’y a donc aucun droit de licence à verser. Cependant, il se pourrait qu’on ait besoin de serveurs plus importants, selon la quantité et la taille des documents à traiter et à stocker.
Licence d’exploitation
Les codes et les configurations de la Solutions type sont tous couverts par la licenceApache 2.0.