Le Propulseur Numériser l’espace physique propose une solution qui, après déploiement, permettra à l’utilisateur d’observer et d’étudier comment un système Bluetooth basse consommation de localisation en temps réel (BLE RTLS) et Kibana résolvent le problème qui consiste à déterminer automatiquement qui/quoi occupe tel ou tel espace dans l’entreprise et où/comment. Ce document décrit la solution et la manière d’utiliser cette technologie évoluée.
Introduction
Énoncé du problème
L’Internet des objets promet beaucoup, mais par-dessus tout, il laisse entrevoir la capacité, pour l’ordinateur, d’observer le monde physique sans aucune intervention de l’être humain. Saisir des données est une tâche fastidieuse et, pour bon nombre d’applications, demander à quelqu’un de le faire pour que l’ordinateur fonctionne plus efficacement s’avère peu pratique, voire irréalisable.
S’il pouvait identifier, situer et analyser les gens, les produits et les lieux par lui-même, peu importe l’endroit, grâce à l’apprentissage machine, l’ordinateur nous aiderait à réduire le volume de déchets, à accroître la productivité, à mettre un terme aux nuisances et à vivre une expérience plus enrichissante.
Grâce à la récente prolifération des articles radio-identifiables, plus précisément ceux respectant les normes RFID BLE et RAIN, il est de plus en plus rentable d’observer les humains occupant un espace au moyen d’un ordinateur recueillant les données transmises par les téléphones intelligents, des articles d’électronique vestimentaire ou d’autres objets comme des étiquettes d’identification par radiofréquence (RFID) peu coûteuses. D’autre part, les infrastructures capables de détecter ces signaux ne cessent de se multiplier. Souvent, il ne manque qu’un logiciel et son intégration pour tout réunir et permettre à l’ordinateur de « numériser » l’espace physique en temps réel.
Bien qu’on trouve sur le marché des produits et des solutions qui « numérisent » un élément ou un autre de l’espace physique dans un but très précis, une myriade d’applications complémentaires demeure sans solution. Une approche pour y remédier consisterait à utiliser un logiciel qui « numérise » tout ce qui peut l’être et procure des interfaces d’application (API) que partageront et exploiteront des logiciels spécifiques.
La Solution type
Nous illustrerons comment les technologies BLE RTLS et Kibana permettent de recueillir et de signaler automatiquement les données sur les activités physiques d’une entreprise.
Aperçu
La Solution type « numérise » n’importe quel espace physique et ses occupants, autant que faire se peut. Elle procure les API avec lesquelles on accède à l’information en temps réel sur qui/quoi se trouve où/comment, ce qui facilite le développement de logiciels d’application spécifiques.
En soi, la solution permet la coexistence de nombreuses applications complémentaires qui, chacune, utiliseront un flux Web standard de données venant des infrastructures physiques partagées. La PME n’aura donc pas à acquérir de vastes connaissances sur le matériel et les logiciels à la base des technologies RTLS, RFID et M2M (communication entre machines), si bien qu’elle pourra se concentrer sur le développement d’applications dans son domaine d’expertise.
Il est facile de configurer le logiciel pour qu’il ingère les données radio en temps réel décodées qui émanent d’une gamme de dispositifs. Les API REST et Socket.io du logiciel permettent d’exploiter les données dans leur contexte. Le logiciel autorise une connexion modulaire aux bases de données et aux plateformes courantes, plus exactement l’intégration d’Elasticsearch et de Kibana. Enfin, il comprend diverses applications Web qui illustrent le potentiel des flux de données et aident l’utilisateur à explorer et à mieux saisir le logiciel.
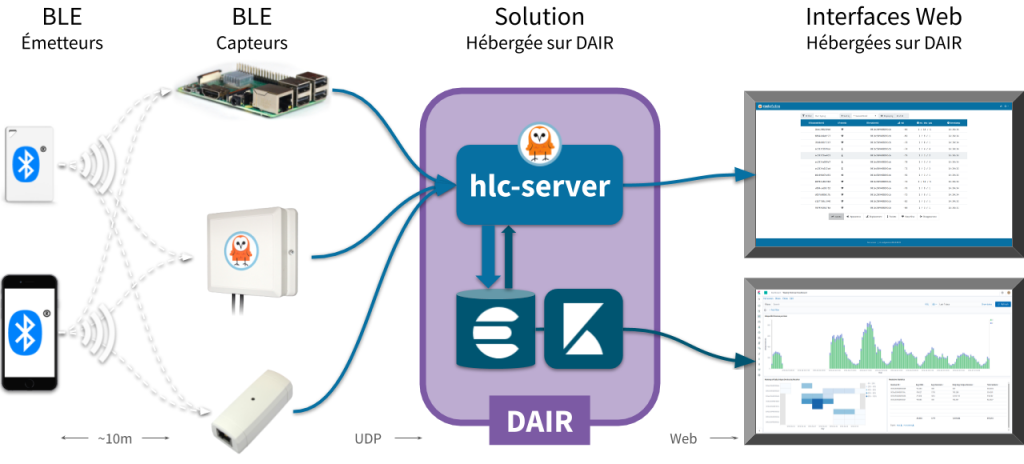
Le diagramme ci-dessous illustre la structure de la Solution type.
Diagramme de la solution
Description des composants
Le tableau que voici résume les principaux composants employés par la solution.
Composant
Résumé
Émetteurs BLE
Dispositifs Bluetooth basse consommation qui émettent spontanément les paquets publicitaires. Il peut s’agir de téléphones intelligents, d’articles d’électronique vestimentaire, de détecteurs de clés, de balises, d’électroménagers intelligents, etc. (lire BLE as Active RFID)
Récepteurs BLE
Passerelles qui captent les paquets publicitaires des dispositifs BLE et, dans la Solution type, les relaient à l’instance du logiciel pour traitement et agrégation (à savoir, Raspberry Pi 3+, Owl-in-One)
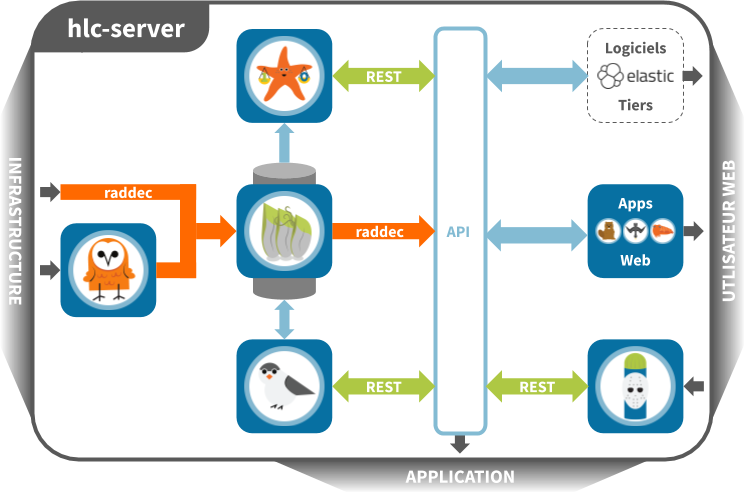
Logiciel de source ouverte combinant les modules ouverts de la source reelyActive (voir le diagramme plus bas) qui mettront en œuvre la solution. Ingère, traite et agrège les données radio décodées des diverses sources à destination des API à double effet avec lesquelles on observe en temps réel qui/quoi est où et comment.
Logiciel de source ouverte permettant de récupérer, visualiser et signaler les données. Lire Kibana integration overview dans reelyActive pour voir comment procéder pour les rapports et les analyses.
Web Interfaces
Le serveur hlc et Kibana proposent des interfaces conviviales pour observer, manipuler et signaler les données en temps réel ou enregistrées.
Démonstration de la technologie
Cette partie illustre comment fonctionne le logiciel Hyperlocal Context Server (hlc-server). Recourir à la technologie RTLS est tentant, car elle automatise la collecte des données sur les activités physiques de l’entreprise, ce qui permet de tirer plus facilement les conclusions sans lesquelles celle-ci ne pourra continuer à s’améliorer.
La démonstration indique comment déployer le logiciel RTLS, la base de données et les logiciels d’analyse dans le nuage de l’ATIR.
Déploiement et configuration
On suppose que vous avez pris les mesures qui suivent avant de déployer la Solution type :
vous avez créé une règle pour les groupes de sécurité vous permettant d’accéder aux machines virtuelles (MV) établies dans le Nuage de l’ATIR au moyen des protocoles HTTP (port80) et HTTPS (port 443) à partir de n’importe quelle source extérieure (0.0.0.0/0);
vous avez créé une règle pour les groupes de sécurité autorisant la connexion de Kibana (5601) et de HLC (port3001) aux MV établies dans le Nuage de l’ATIR à partir de n’importe quelle source extérieure (0.0.0.0/0);
vous avez créé un groupe de sécurité vous donnant accès aux MV établies dans le Nuage de l’ATIR avec le protocole SSH (port22 du protocole TCP) à partir de l’adresse IP que vous utilisez;
vous avez votre clé SSH privée donnant accès aux MV du Propulseur de l’ATIR.
Ouvrez une séance sur votre compte ATIR d’AWS en suivant les instructions que vous a procurées l’équipe de l’ATIR.
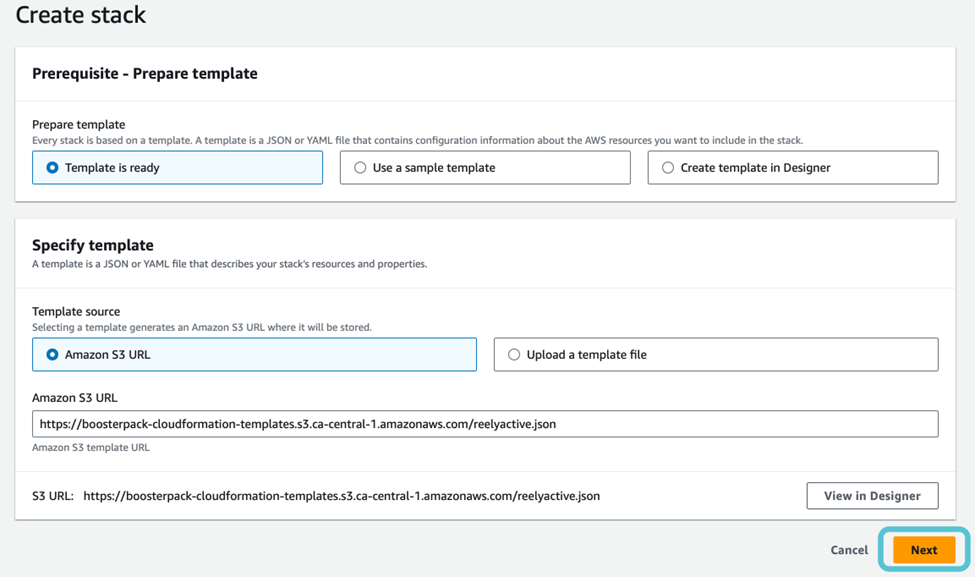
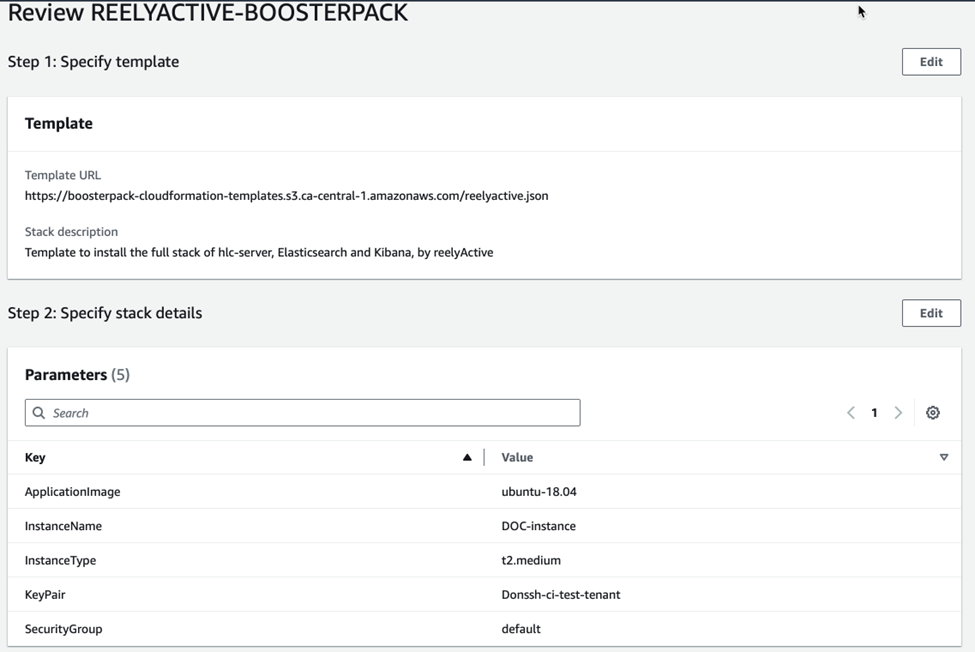
Cliquez DÉPLOYER pour lancer le Propulseur avec la pile CloudFormation d’AWS.
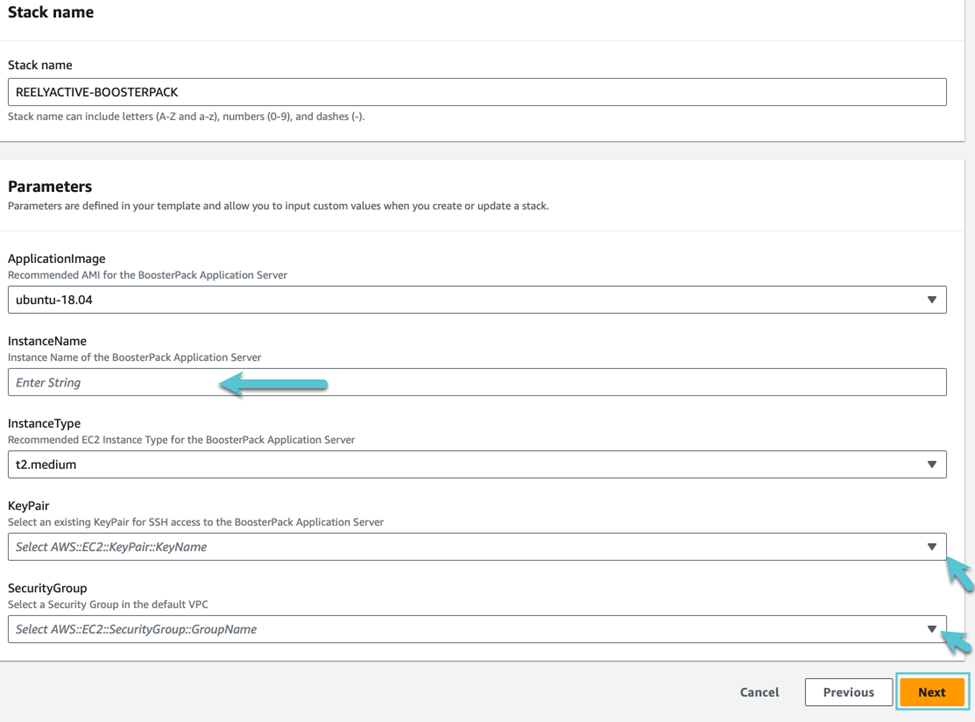
Cliquez Suivant pour passer à la deuxième étape de CloudFormation et remplissez le formulaire de configuration. Dans le champ InstanceName, donnez un nom unique à l’instance de votre application Web.
Cela fait, cliquez Suivant pour passer à la troisième étape. Cette partie permet de configurer d’autres options, plus avancées, mais inutiles dans le cas qui nous intéresse.
Cliquez Suivant, au bas de la page, pour sauter cette étape et passer à la dernière de CloudFormation.
La dernière partie permet de vérifier la configuration du Propulseur et d’y apporter des changements avec le bouton Modifier, si besoin est. Une fois que la configuration vous convient, cliquez Soumettre, au bas de la page, pour déployer le Propulseur.
Le déploiement commence par la création d’une nouvelle instance. Le reste est automatique. Suivre le développement de l’instance AWS n’est possible qu’avec les onglets Événements et Ressources de la console CloudFormation. Pour vous connecter à l’instance par la suite, vous aurez besoin de votre clé ssh et de l’adresse IP indiquée dans l’onglet Sorties.
Sélectionnez le menu
Infrastructure.
Sélectionnez l’option Réseau.
Cliquez l’onglet Groupes de sécurité.
Cliquez le Nom du groupe de sécurité du nuage AWS pour en modifier les règles.
Dépannage
Connectez-vous à votre instance dans le nuage avec le protocole SSH et exécutez les commandes qui suivent.
Pour vérifier l’avancement du déploiement : $ cat /var/log/boosterpack.log
Pour vérifier l’état des services en cours d’exécution : $ sudo systemctl status elasticsearch.service
$ sudo systemctl status kibana.service
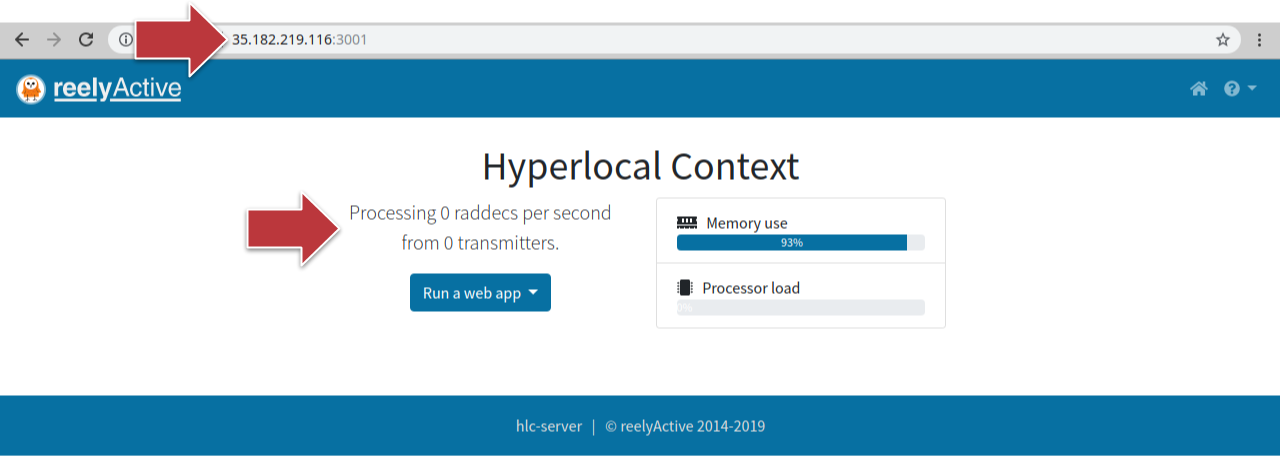
À présent, vous pouvez diriger le navigateur vers l’adresse IP de l’instance, par le port 3001, afin d’accéder à l’application Web HLC. Exemple illustré ci-dessous : http://15.156.83.137:3001:
Une page d’accueil semblable à celle qui apparaît ci-dessus s’affichera à l’écran. L’absence de données est normale puisqu’aucun appareil RTLS n’enverra d’information au logiciel tant qu’on ne l’aura pas configuré.
Vous devriez voir une page d’accueil similaire à celle-ci sur l’écran. Il est normal que le logiciel ne traite aucune donnée, puisque le système RTLS doit être configuré avant de transmettre des données.
Transmission des données à l’instance de la Solution type
Le logiciel hlc-server attend que les paquets de données (binaires) décodées raddec (RADio DECoding) traversent le port 50001 avec le protocole UDP. Il y a plusieurs façons d’envoyer des raddecs à l’instance. On peut, par exemple, recourir à un dispositif intégré comme Owl-in-One, à un appareil commercial comme un Raspberry Pi ou simplement à un logiciel.
Les Pi 3, Pi 4 et Pi plus récents de Raspberry incorporent une radio Bluetooth à faible consommation d’énergie (BLE) que vous pourrez configurer afin d’exploiter le logiciel de source ouverte de reelyActive. Pour cela, suivez ce tutoriel (en anglais).
Après avoir configuré le Pi, suivez les instructions ci-dessous pour en faire autant avec la radio intégrée.
Le logiciel du serveur hlc détectera automatiquement les données ambiantes transmises par le dispositif BLE pourvu qu’une instance de barnowl-hci soit ouverte et transmette les données. Les instructions qui suivent expliquent comment installer cette instance et faire en sorte qu’elle se mette en marche automatiquement chaque fois qu’on allume le Pi.
Installation de barnowl-hci
À partir du terminal avec lequel vous vous connectez au Pi avec le protocole SSH, effectuez ce qui suit.
Créez un répertoire reelyActive et faites en sorte que le système pointe vers ce répertoire avec les commandes qui suivent :
$ mkdir ~/reelyActive
$ cd ~/reelyActive
Clonez le dépôt barnowl-hci avec la commande suivante :
Modifiez le dossier barnowl-hci avec la commande suivante :
$ cd barnowl-hci
Installez toutes les dépendances npm avec la commande suivante :
$ npm install (l’exécution prend environ une minute)
Attribution de privilèges radio
Accordez aux programmes Node.js le privilège de lancer un balayage avec la commande que voici : $ sudo setcap cap_net_raw+eip $(eval readlink -f `which node`)
Lancement de Barnowl
Lancez barnowl-hci une fois pour vous assurer que le programme capte bien les données ambiantes :
npm start enverra des sorties de décodage radio (raddecs) à la console pour effectuer un essai rapide et grossier;
npm run forwarder transmettra des raddecs à l’instance configurée avec CloudFrmation. Au lieu d’envoyer les raddecs par protocole UDP à une instance Pareto Anywhere éloignée, commencez le script avec : npm run forwarder xxx.xxx.xxx.xxx où xxx.xxx.xxx.xxx correspond à l’adresse IP de l’instance éloignée.
Pour arrêter barnowl, saisissez Ctrl+C.
Activation de barnowl-hci-forwarder en tant que service
Configurez systemd pour qu’il exécute le service barnowl-hci-forwarder en modifiant le répertoire de travail et en ajoutant l’adresse IP à la fin de la commande NPM. Les trois modifications requises apparaissent en caractères gras :
$ vi units/barnowl-hci-forwarder-pi.service
modifier les données suivantes dans le fichier :
[Unit]
Description=Bluetooth HCI scan forwarder by reelyActive
ExecStart=/usr/bin/npm run forwarder 15.156.83.137
Restart=on-failure
User=dmccullo
[Install]
WantedBy=multi-user.target
Sauvegardez le fichier en enfonçant la touche Esc puis en saisissant wq!
Copiez le fichier de l’unité dans le répertoire systemd avec la commande : $ sudo cp units/barnowl-hci-forwarder-pi.service /lib/systemd/system
Activez le service barnowl-hci-forwarder avec la commande : $ sudo systemctl enable barnowl-hci-forwarder-pi.service
Lancez le service barnowl-hci-forwarder avec la commande : $ sudo systemctl start barnowl-hci-forwarder-pi.service
Dorénavant, chaque fois qu’il s’allume, le Pi vérifiera automatiquement et de façon continue si des dispositifs ambiants émettent des données et transmettra celles-ci à Pareto Anywhere.
Si besoin est, on peut désactiver ce service avec la commande : $ sudo systemctl disable barnowl-hci-forwarder-pi.service.
Voilà. Vous disposez d’un service Barnowl détectant les données Bluetooth dans votre espace de travail et les transmettant à votre instance.
Transmission avec un logiciel
Vous pouvez produire et transmettre un paquet raddec avec le code Node.js que voici.
client.send(raddec, 0, raddec.length, 50001, ‘35.182.219.116’); // Set IP address!
Collez ces lignes dans un fichier que vous appellerez forward.js, puis, de la ligne de commande, exécutez node forward. Un raddec sera expédié à l’instance de la Solution type par UDP.
Observation des données dans Kibana
Les données pourront être observées dans Kibana à deux conditions.
Au moins un paquet de données radio décodées (raddec) a été relayé à l’instance de la Solution type (voir plus haut).
Kibana est configuré pour qu’on puisse y accéder par le Web (il n’est accessible que sur localhost par défaut).
Configuration de Kibana en vue d’un accès à distance
Pour accéder à Kibana à distance, en modifiant sa configuration comme suit :
ajouter ssh dans l’instance de la Solution type (par ex., ssh [email protected]) – on peut aussi se servir de la console Web sur l’onglet Console en vue instance pour cela
ouvrir le fichier kibana.yml et le modifier avec la commande sudo vi /etc/kibana/kibana.yml
ajouter host: “0.0.0.0” à la fin du fichier
sauvegarder le fichier
relancer Kibana avec la commande sudo systemctl restart kibana.service
À présent, vous devriez pouvoir naviguer sur Kibana par le port 5601 de l’instance de la Solution type (par ex., 35.182.219.116:5601).
Créer un index des raddec dans Kibana
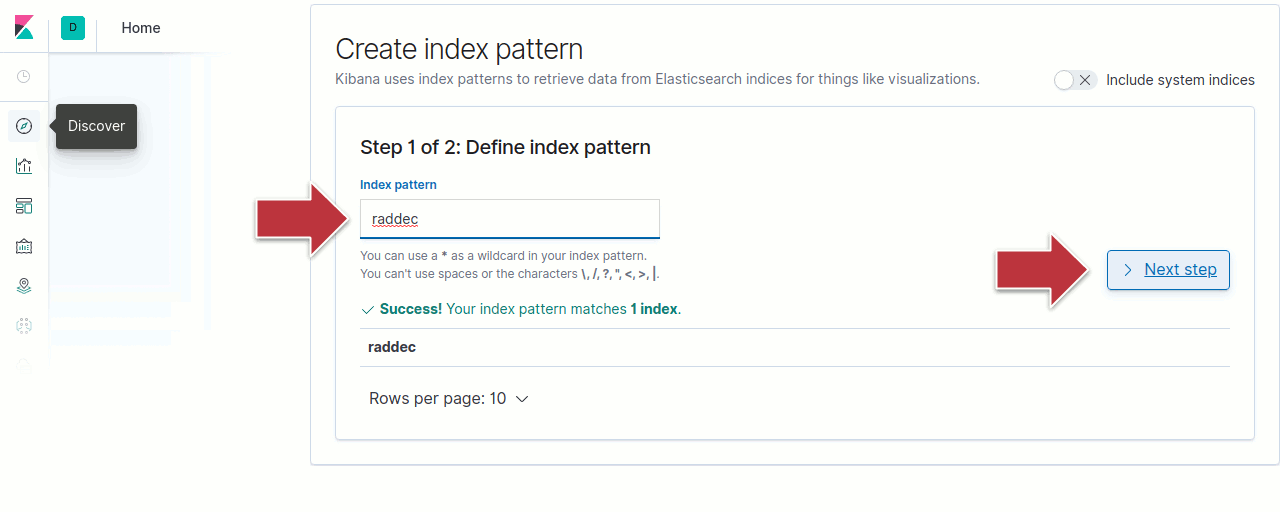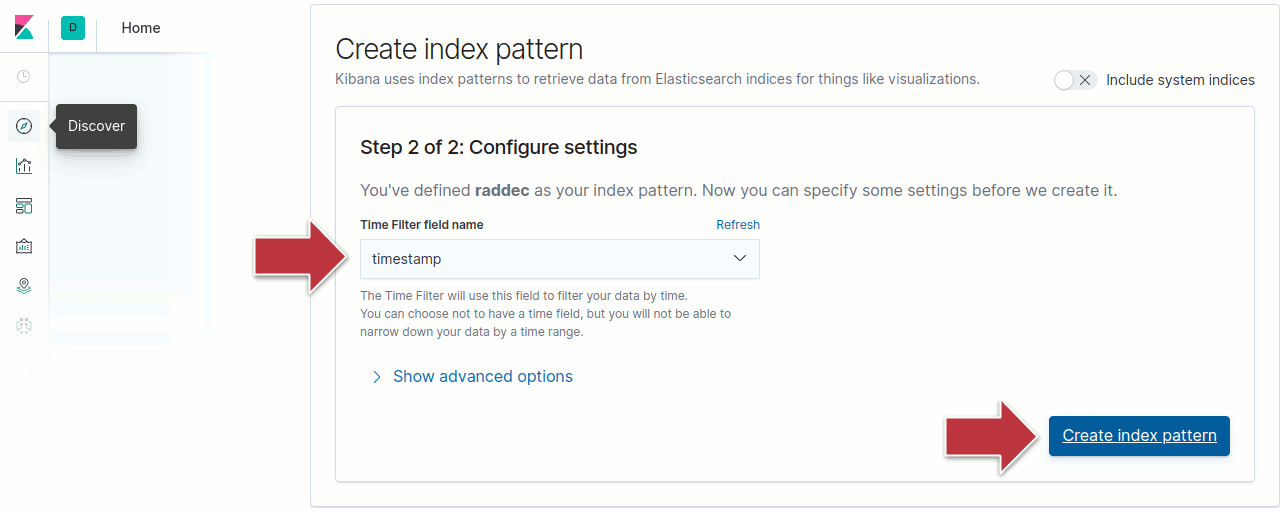
Dans Kibana, cliquez l’icône Discover sur la barre de gauche pour passer à la page « Create index pattern ».
Tapez raddec dans la fenêtre « index pattern », puis cliquez Next Step pour continuer.
Sélectionnez timestamp dans le menu déroulant Time Filter et cliquez Create index pattern pour continuer.
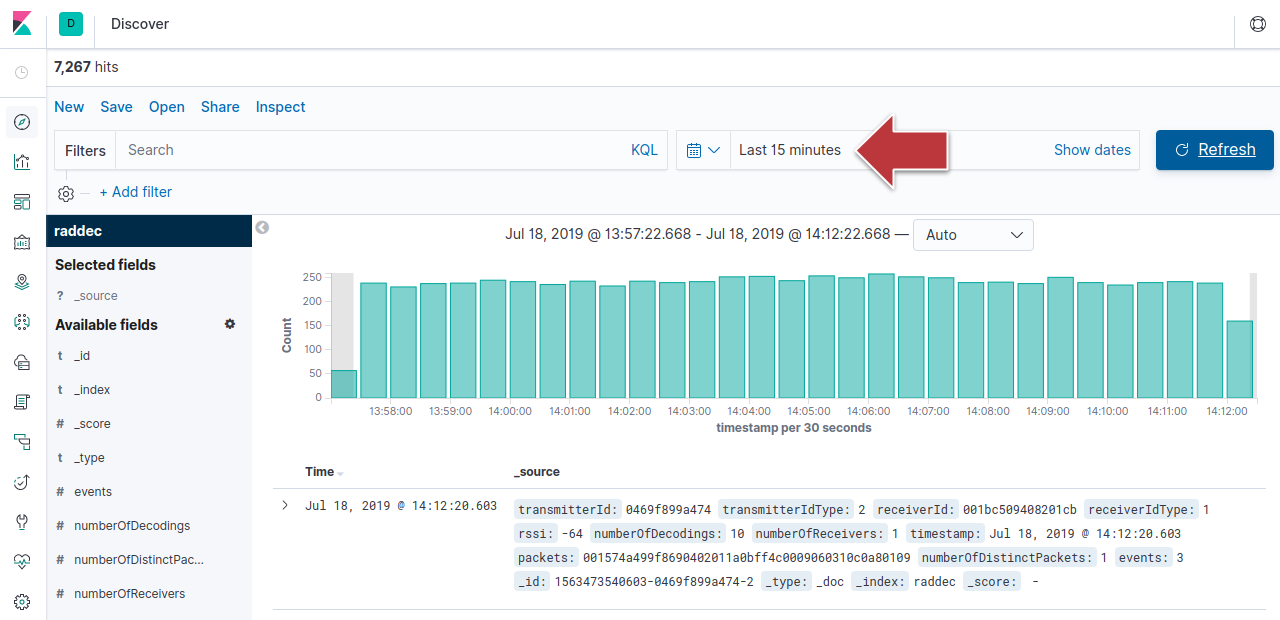
Cliquez de nouveau l’icône Discover et observez les données raddec (s’il le faut, modifiez la plage horaire pour vous assurer qu’il y a des données)
Produire des rapports et visualiser les données avec Kibana
Pour libérer des ressources en mode Instances, sélectionnez l’instance puis, à partir du bouton du menu ACTIONS, sélectionnez Delete. À l’invite, choisissez Release EIP et cliquez le bouton DELETE.
Considérations d’ordre technique
This section describes considerations for usage and adaptation of the reference solution.
Cette partie décrit ce dont il faut tenir compte pour utiliser et adapter la solution de référence.
Déploiement
Le logiciel de source ouverte hlc-server peut être déployé sur à peu près n’importe quoi, d’un Raspberry Pi à un serveur d’infonuagique de pointe, car il a été conçu pour être accessible et polyvalent. Une unité centrale de traitement (UCT) adéquate suffira à obtenir une bonne performance jusqu’à un certain débit de données de localisation en temps réel. Au-delà de ce point cependant, il vaut mieux optimiser l’architecture qu’augmenter la capacité de l’UCT. Nous en discutons plus bas, dans les considérations de mise à l’échelle.
Le logiciel d’Elastic peut aussi être déployé sur une autre machine que le hlc-server, ce qui permet d’adapter les ressources à des besoins très différents.
Technologies de rechange
En ce qui concerne l’équipement de localisation en temps réel (dispositifs qui détectent et relaient les paquets radio au logiciel RTLS), les fournisseurs et les technologies ne manquent pas. La technologie RFID active la plus répandue est certainement BLE (Bluetooth basse consommation) et sa contrepartie passive est RAIN RFID. Un appareil BLE disponible dans le commerce comme le Raspberry Pi 3 peut servir de récepteur et relayer les paquets de données au logiciel de source ouverte. Pour la technologie RAIN RFID, on aura besoin du matériel plus complexe que proposent divers fournisseurs.
À notre connaissance, il n’existe pas de solution de rechange au logiciel RTLS générique de source ouverte.
Pour ce qui est des bases de données et des logiciels d’analyse, les solutions de rechange aux logiciels d’Elastic abondent. Dans la plupart des cas, rédiger un programme de connexion (semblable à barnacles-elasticsearch) pour l’intégrer à une autre base de données ne s’avérerait guère compliqué.
Architecture des données
La Solution type produit des données, plus précisément un flot de points représentant qui/quoi se trouve où/comment. Dans une application en temps réel pure (sans stockage de données), la seule chose à prendre en considération serait l’exploitation des données à mesure qu’elles sont produites. Beaucoup d’autres considérations entrent toutefois en jeu dans les applications qui stockent les données.
Où stocker?
Le type de base de données ou de support qui conservera les données historiques aura une incidence sur le coût et la performance au niveau de la récupération et de la manipulation des données en question. L’endroit où se trouvent les ressources informatiques qui entreposent les données pourrait aussi entrer en compte. Des contraintes juridiques ou contractuelles pourraient faire en sorte que les données doivent être gardées dans le pays ou la région où elles ont été engendrées.
Combien de temps?
Un système de localisation en temps réel fonctionnant en permanence crée un volume considérable de données qui, si elles ne sont pas archivées ou détruites au bout d’un certain temps, réduiront la performance du système et entraîneront des coûts supplémentaires assez élevés.
Quoi garder?
Un dispositif BLE RTLS recueillera en temps réel les données sur la localisation de tous les autres dispositifs BLE situés dans l’espace balayé. Quand on veut surveiller des dispositifs précis (les biens marqués) et ignorer les autres (téléphones intelligents, articles d’électronique vestimentaire), dresser une liste blanche d’appareils devrait suffire pour réduire la somme de données conservées, donc les coûts.
Sécurité
La Solution type est conçue pour sa commodité et l’expérimentation, plutôt qu’un déploiement sûr dans un environnement de production. Par défaut, le logiciel acceptera les données entrantes (sous forme de paquets UDP) de n’importe quelle source et donnera accès à l’API sans authentification.
Il revient à l’utilisateur qui le souhaite d’assurer la protection des données qui entrent et qui sortent. Dans le premier cas, la solution la plus simple consiste à activer les règles du pare-feu (par ex., ufw sur Ubuntu) pour n’accepter que les paquets UDP venant d’adresses IP précises. Pour les données sortantes, on pourrait installer et configurer NGINX afin d’exiger une authentification rudimentaire avant d’autoriser l’accès à l’API et aux applications Web.
Réseau
Il n’y aucune considération importante dont il faut tenir compte sur ce plan, outre les pratiques éprouvées recommandées dans l’industrie.
Mise à l’échelle
La Solution type peut être mise à l’échelle dans une mesure restreinte, selon le débit des données et les ressources disponibles (principalement l’UCT). Au-delà d’un certain point, il est plus efficace d’établir une architecture parallèle que d’augmenter la capacité de l’UCT.
Avec une application à débit élevé, il pourrait être plus efficace de lancer plusieurs instances du module barnacles avec le logiciel hlr-server et de répartir la charge entre eux, en fonction des identifiants radio du flux de données entrant. En d’autres termes, plusieurs instances barnacles fonctionneront de façon totalement indépendante pourvu que les données de chaque dispositif RFID soient toujours acheminées vers la même instance.
En ce qui concerne Elasticsearch et Kibana, on recommande d’observer les pratiques exemplaires pour les logiciels d’Elastic avec les applications à fort débit. L’exploitation de ces logiciels sur la même machine que hlc-server, comme on le fait dans la Solution type, n’est possible que jusqu’à une échelle restreinte. Le service Elasticsearch offre une souplesse nettement plus grande, même si un prix s’attache à cela.
Disponibilité
La Solution type n’est pas spécifiquement conçue pour optimiser la disponibilité, mais sa disponibilité demeure grande tant qu’on ne dépasse pas les limites de mise à l’échelle. Quand la disponibilité est un facteur crucial, on préconise le lancement d’instances en parallèle, un peu comme on le décrit à la partie « Mise à l’échelle ».
Interface utilisateur (IU)
Le logiciel hlc-server de la Solution type comprend plusieurs applications Web de source ouverte pouvant servir d’interface. Ces applications sont rédigées en HTML, CSS et vanilla JS (sans cadres) pour une lecture et des modifications/extensions plus faciles. L’utilisateur est encouragé à adapter et à élargir ces applications Web, puis à les partager avec le reste de la collectivité.
La plupart des applications Web en temps réel sont bâties avec beaver.js, ce qui affranchit le développeur des interactions avec l’API WebSocket et lui permet de se concentrer sur l’application proprement dite.
API
Les API qui accompagnent le logiciel hlc-server de la Solution type suffisent dans la majorité des cas. Si on a besoin d’une API différente ou plus importante pour accéder aux données, on recommande de créer une interface barnacles. Pour que l’API ingère les données venant du dispositif RTLS d’une tierce partie, il serait préférable de la créer avec le logiciel barnowl listener.
Les API peuvent aussi être enveloppées avec une couche de sécurité ou d’authentification.
Coût
La Solution type est très exigeante au niveau des entrées et sorties, et la plupart des coûts dérivent du traitement continu des données en temps réel. Outre l’optimisation des spécifications de l’équipement d’infonuagique pour gérer les coûts, une solution de rechange intéressante consisterait à repousser autant que possible le traitement en marge du nuage, pour l’alléger.
On parvient souvent à un bon équilibre périphérie/nuage en exploitant barnowl en marge et barnacles à l’intérieur du nuage. Dans un tel cas, barnowl retient les données une seconde (par défaut), ce qui entraîne une importante compression (sans perte) et atténue les exigences au niveau de la bande passante et du traitement en amont.
Licence d’exploitation
Le logiciel hlc-server de source ouverte utilisé par la Solution type est assorti d’une licence du MIT permissive qui, pour l’utilisateur ou le développeur, se résume à la condition suivante :
Inclure la mention de droit d’auteur et d’autorisation qui précède à toutes les copies intégrales ou importantes du logiciel.
Les versions source ouverte d’Elasticsearch et de Kibana sont assorties d’une licence Apache Version 2.0. Les autres versions de ces produits utilisent la licence d’Elastic.
Code source
Le code source du logiciel hlc-server et les logiciels reelyActive sur lesquels il repose est disponible sur le compte GitHub de reelyActive à github.com/reelyactive
Le code des versions source ouverte d’Elasticsearch et de Kibana se trouve sur le compte GitHub d’Elastic à github.com/elastic.