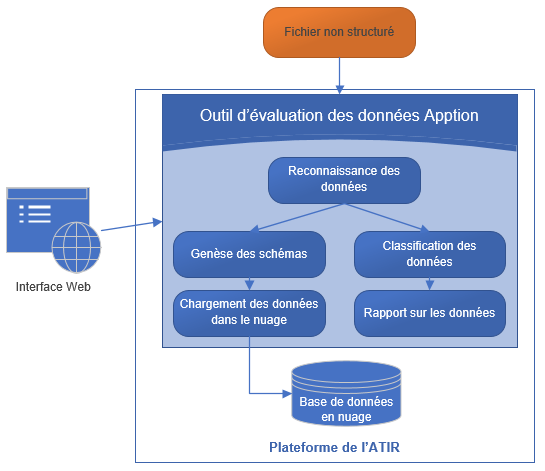
Travailler avec le code source
La section que voici explique comment configurer l’environnement de développement pour tester le code de l’application, le modifier et déployer la nouvelle version afin d’en vérifier les résultats. Pour travailler avec le code source, vous devrez l’extraire du dépôt de CANARIE (Gogs) et le lancer dans Visual Studio 2019 (environnement de développement interactif ou IDE). L’IDE vous donnera accès aux options suivantes pour l’exécution :
- exécution de l’application sur le Web local
- exécution autonome sur Electron
TPour lancer l’application Web (voir l’écran ci-dessous), enfoncez le bouton de lecture vert.

Prérequis
Vous devrez d’abord installer ce qui suit.
1. Visual Studio 2019 de Microsoft
2. .NET Core 3 Tools – disponible sur https://dotnet.microsoft.com/download/dotnet-core/
3. Version la plus récente du module Blazor Language Services, disponible sur Visual Studio Marketplace à l’adresse : https://marketplace.visualstudio.com/items?itemName=aspnet.blazor
4. Docker for Developers, disponible à l’adresse https://www.docker.com/get-started
5. PowerShell de Microsoft
Les quatre premiers logiciels sont essentiels pour bâtir l’application Apption dans Visual Studio.
Les deux derniers permettent de transférer les données binaires d’Apption à l’image Docker dans laquelle elles seront distribuées.
Créer une image Docker
Cette étape suppose que les fichiers source d’Apption ont déjà été clonés localement et qu’il est possible d’ouvrir la solution pour la modifier dans Visual Studio. Les prérequis 1 à 4 doivent aussi avoir été remplis.
L’environnement .Net Core et le module Blazor autorisent le lancement d’une tâche exécutable Windows sur un hôte Linux. Il est donc possible de bâtir une image Docker sur le système d’exploitation par défaut Linux.
L’image Docker que nous créerons en est une fournie par Microsoft dans laquelle .Net Core et Blazor ont été installés à l’avance. Il suffira d’y ajouter les bibliothèques et les tâches exécutables supplémentaires. En résultera une image Docker que n’importe quel client Docker pourra extraire et utiliser.
Publication ou construction locale de l’outil Apption
- Cliquez à droite sur le projet « WebAppMaterialize.Server » dans Solution Explorer, puis cliquez « Open Folder in File Explorer» pour ouvrir l’explorateur de fichiers.
- Descendez les répertoires « bin », « Debug » et « netcoreapp2.1 ». Vous découvrirez une série de fichiers .dll, .json et .config, ainsi qu’un fichier baptisé « Dockerfile », sans extension.
- Cliquez l’espace qui suit immédiatement le chemin du répertoire, presque au sommet de l’explorateur de fichiers et enfoncez Ctrl-C pour copier le chemin dans le presse-papiers.
- Revenez à Visual Studio et cliquez à droite sur le projet « WebAppMaterialize.Server » dans Solution Explorer, puis cliquez « Publish…».
- Sélectionnez « FolderProfile» et cliquez l’hyperlien « Configure… ».
- Cliquez la boîte « Target location» et collez-y le chemin du répertoire en enfonçant Ctrl-V.
- Ajoutez « /publish » (sans guillemets) à la fin du chemin et enfoncez le bouton « Save».
Une fois le processus achevé, retournez à l’explorateur de fichiers. Vous devriez voir un nouveau répertoire baptisé « publish » renfermant une cinquantaine de fichiers et trois sous-répertoires. Ceci termine l’étape de la publication ou de la construction locale.
Création d’une image Docker
Avec cette étape, vous créerez une image Docker à partir du répertoire « publish ». L’image utilise les commandes du client Docker dans l’environnement PowerShell.
- Lancez PowerShell à partir du menu Démarrer de Windows.
- Confirmez que Docker a été installé correctement en actionnant la commande « docker version ». Si l’installation s’est bien déroulée, vous verrez un rapport sur la configuration du Client et du Serveur.
- Saisissez « cd “ » (cd suivi d’un guillemet anglais), puis cliquez à droite pour coller ce que vous avez copié dans le répertoire créé à l’étape précédente. Vous devrez peut-être retourner dans l’explorateur de fichiers si le chemin copié précédemment ne figure plus dans la mémoire tampon.
- Ajoutez les guillemets anglais de fermeture (« ” ») puis enfoncez la touche « entrée ».
- Saisissez la commande « ls ». Assurez-vous que le fichier « Dockerfile » (sans extension) figure bien dans la liste.
- Saisissez la commande « docker build -t webappmaterialize . » (n’oubliez pas l’espace suivi d’un point).
- Docker extraira une image Docker de Microsoft et copiera les commandes exécutables du répertoire « publish » pour en créer une nouvelle.
- Saisissez la commande « docker images ».
La dernière commande devrait produire ce qui suit.

Une fois créée, l’image Docker peut être déployée et lancée à partir de n’importe quel client Docker (sur votre machine de développement locale ou dans l’hôte Docker de l’ATIR). Pour lancer l’image Docker que vous venez de bâtir, utilisez la commande que voici :
‘docker run -p 8000:80 --rm -it webappmaterialize’
Vous obtiendrez ceci :
Hosting environment: Production
Content root path: /App
Now listening on: http://[::]:
Application started. Press Ctrl+C to shut down.
Vous pouvez maintenant utiliser l’application Apption (A-DAT) à partir du navigateur situé à l’URL « localhost:8000 ».
Pour stopper le processus, utilisez Ctrl-C.
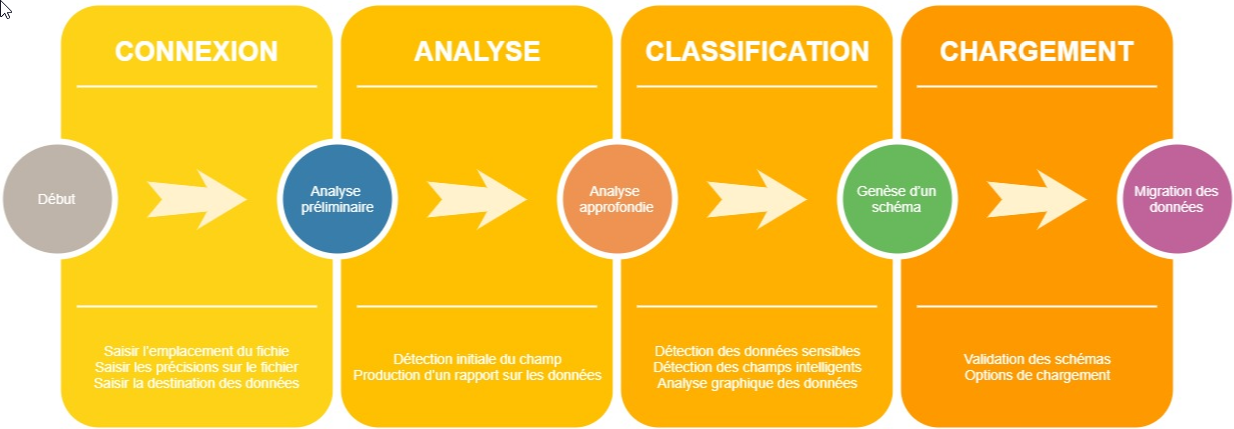
Guide d’utilisation
Une fois déployée, vous pourrez accéder à l’application en saisissant son URL dans un navigateur. La page d’accueil d’Apption (A-DAT) ci-dessous s’affichera à l’écran.
1re étape : se connecter
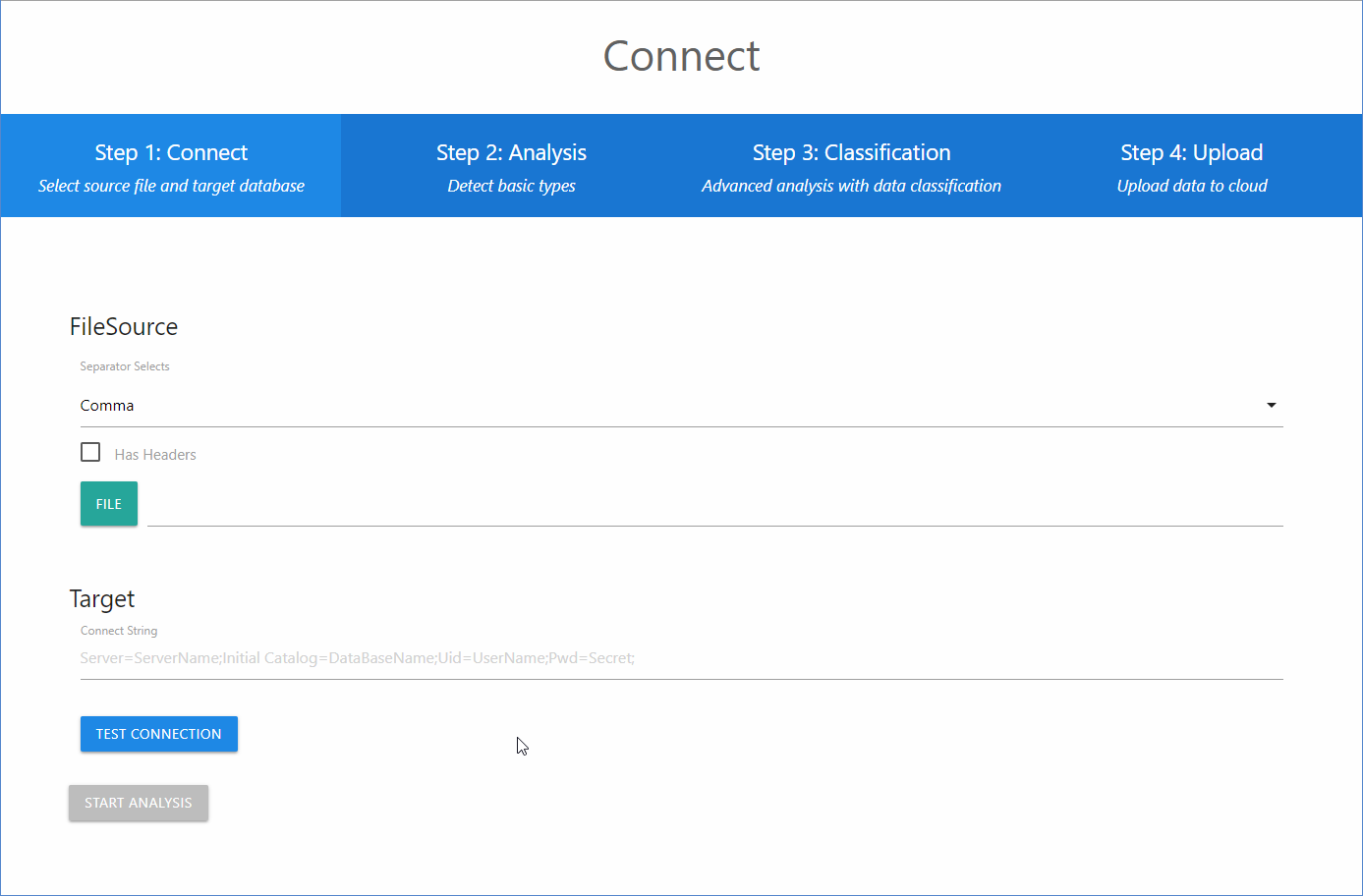
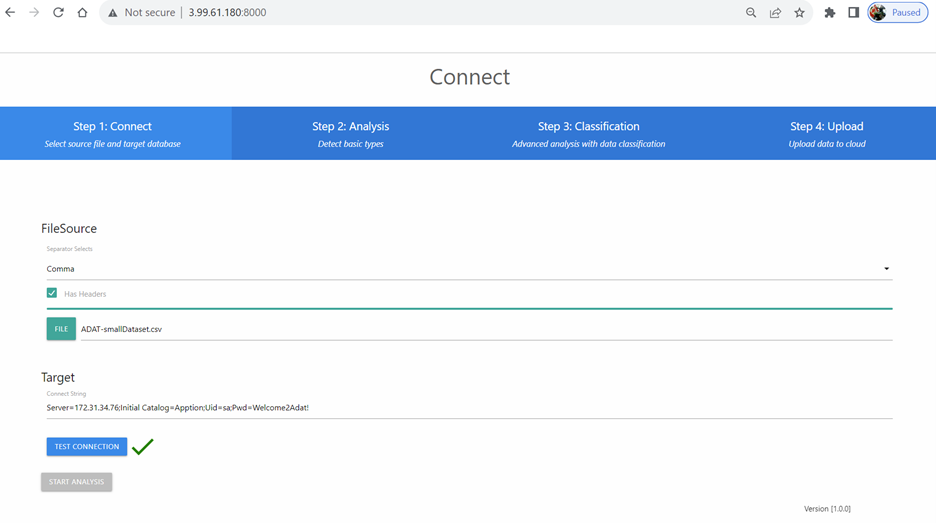
Ceci est la page d’accueil de l’application. Vous y saisirez l’information sur le fichier contenant les données et sur la base de données de destination. Le bouton « Start Analysis » ne sera activé qu’après migration complète du fichier de données. Vous devrez indiquer quel séparateur utiliser dans le fichier et préciser si ce dernier renferme des en-têtes.
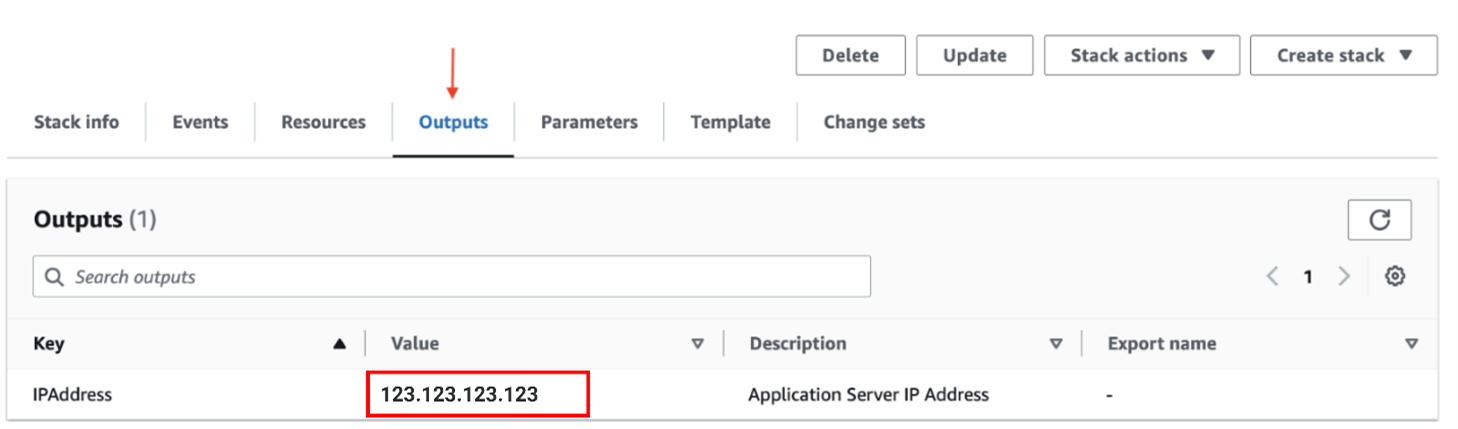
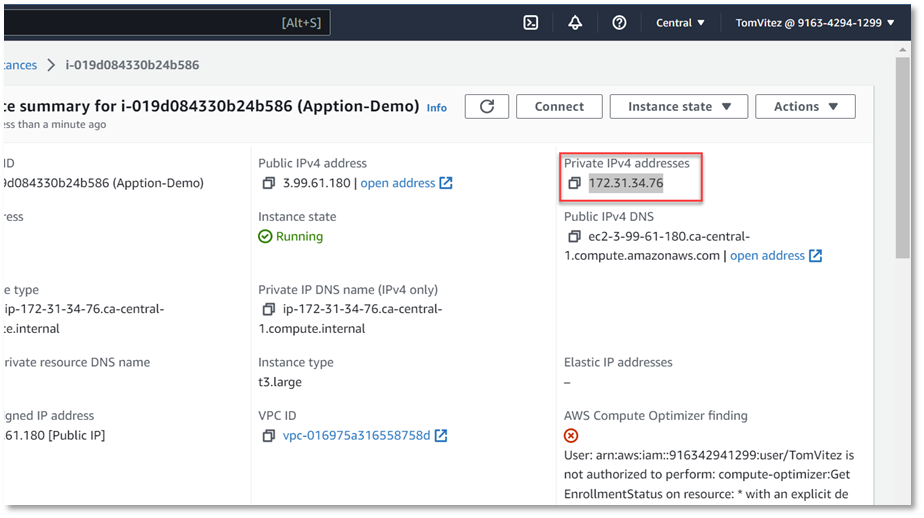
La base de données de destination n’est pas obligatoire, mais vous devez la spécifier si vous voulez y migrer les données du fichier. Indiquez l’adresse IP de la base de données interne dans la chaîne « Target » puisque la connexion s’établit à l’intérieur du nuage. Vous trouverez l’adresse de la base de données interne sur l’écran « Instance Summary », en sélectionnant l’onglet « Network » comme le montre l’image ci-dessous.
Si vous le préférez, vous pouvez aussi analyser les données sans les charger dans la base de données.
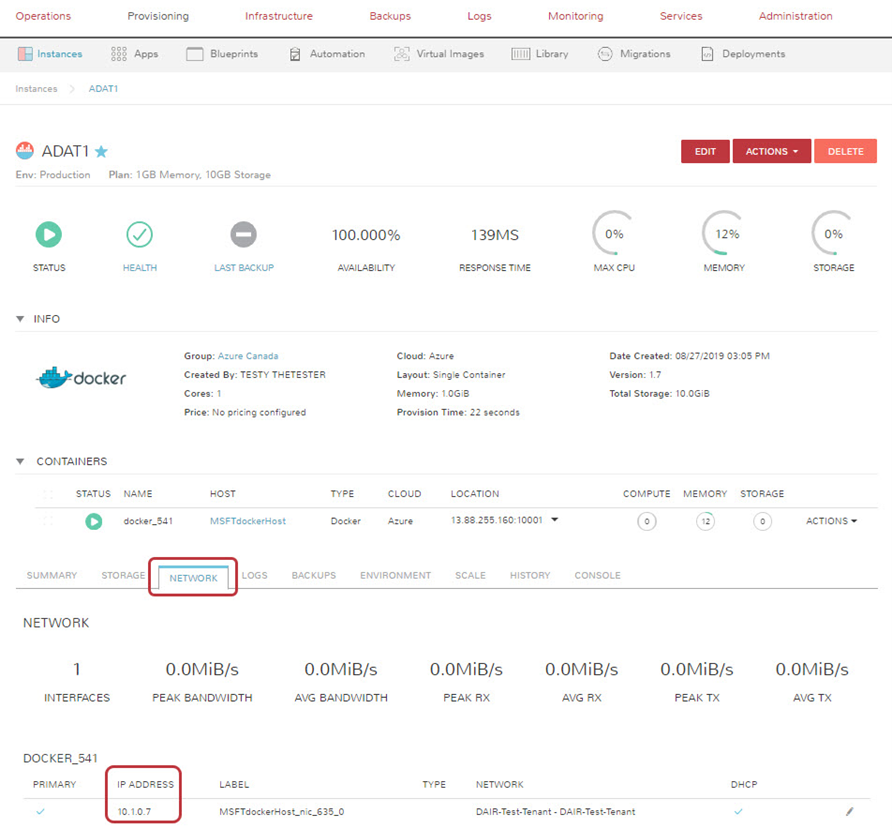
Si vous le préférez, vous pouvez aussi analyser les données sans les charger dans la base de données.
Après avoir saisi les informations requises, cliquez le bouton « Start Analysis » pour lancer l’analyse. La page qui suit illustre ce qui s’affiche à l’écran une fois l’opération terminée.
2e étape : analyser les données
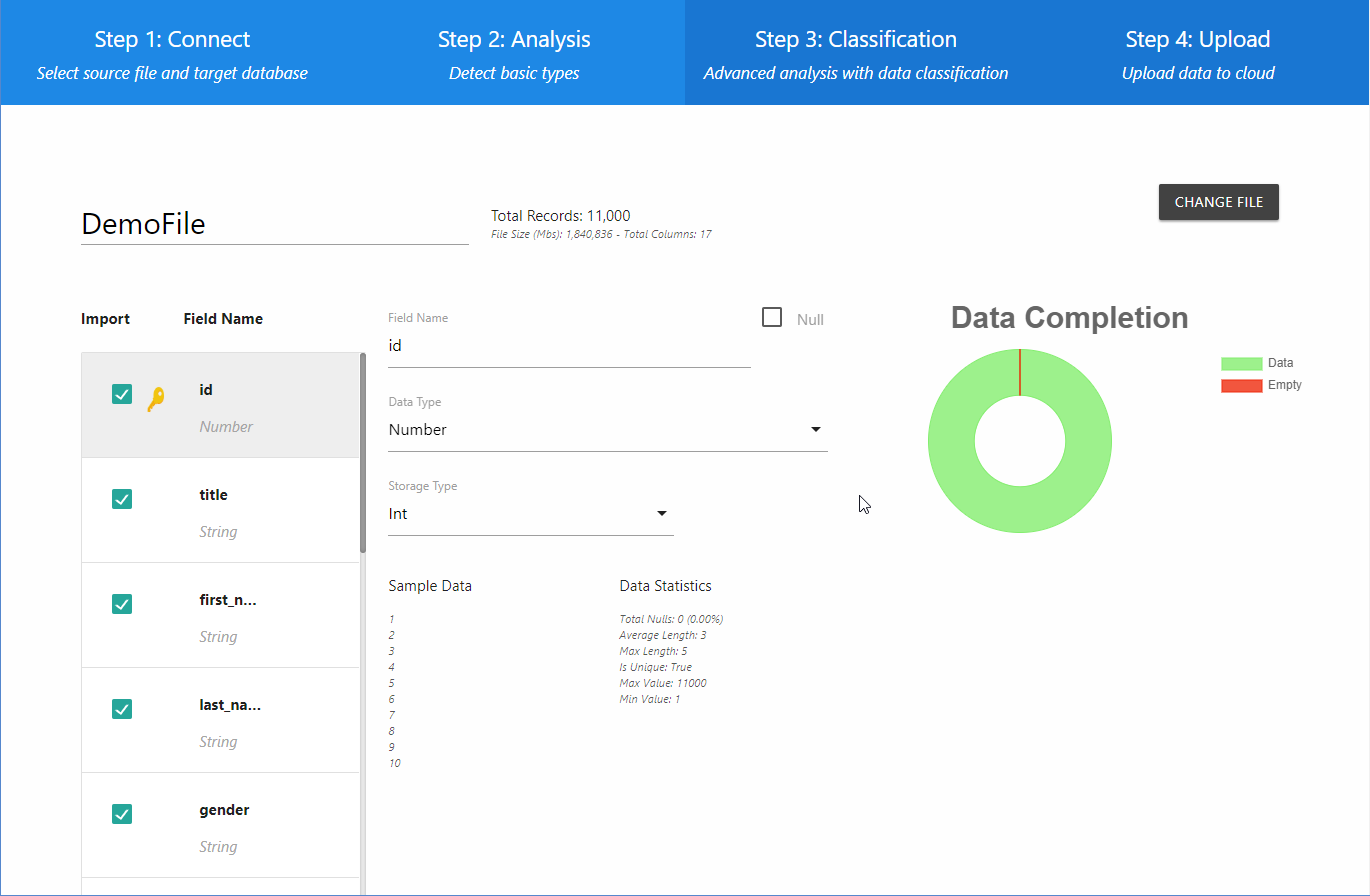
L’écran « Analysis » affiche les résultats de l’analyse préliminaire des données. Les champs apparaissent tous du côté gauche. À droite figurent les précisions sur le champ sélectionné. Vous y verrez notamment son nom, le type de donnée (chaîne ou chiffre) et le genre de stockage possible. Les statistiques et un échantillon des données s’affichent complètement à droite, ce qui permet d’établir si les données sont uniques ou pas. L’analyse préliminaire engendre une structure rudimentaire que vous pouvez néanmoins retenir. Certains utilisateurs préfèrent classer les champs de façon plus précise. Si c’est votre cas, passer à l’étape suivante en cliquant le bouton « Classify Fields » (invisible sur l’illustration), à la fin de la liste des champs, à gauche. Après classification, ce qui suit devrait apparaître sur l’écran.
3e étape : classifier les données
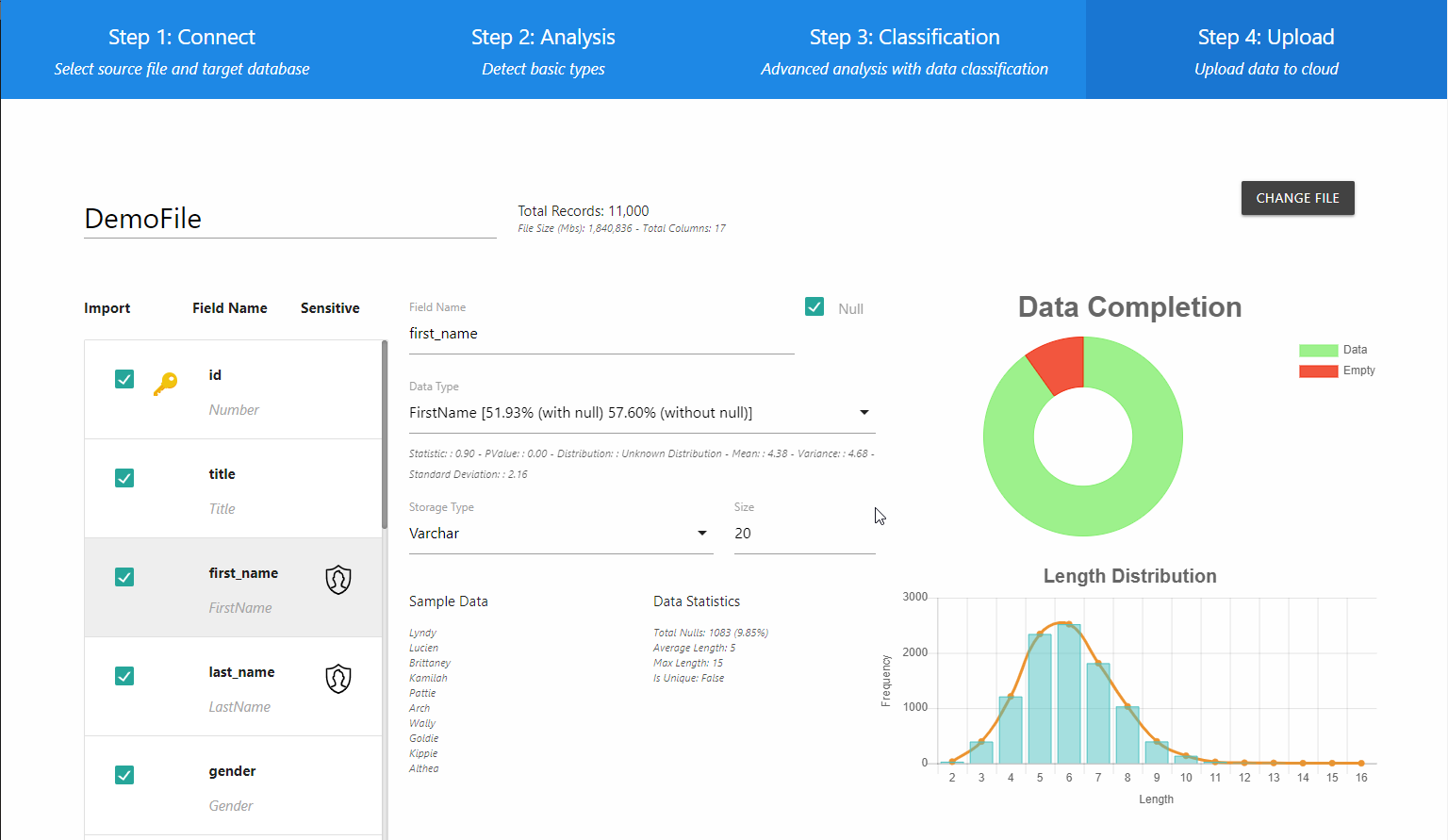
La liste à gauche propose une interprétation plus détaillée du champ. L’application détermine la nature spécifique des données dans chacun et indique à l’utilisateur si le champ contient ou pas des données sensibles en affichant l’icône correspondante dans la colonne « Sensitive ». La liste déroulante « Data Type » énumère toutes les sortes de données en fonction de leur probabilité. D’autres statistiques s’ajoutent à celles qui précèdent sous forme de graphique, ce qui permet de voir les données contenues dans chaque champ. En parcourant la liste, vous verrez aussi un histogramme signalant le degré de probabilité des données (ici, celui du champ FirstName).
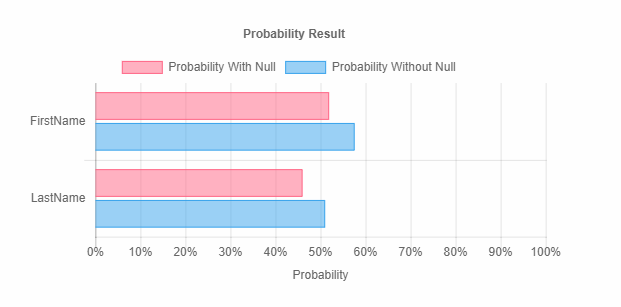
À ce point, vous pourrez apporter divers ajustements au champ ou au fichier, par exemple :
- modifier le nom de tableau dans la base de données;
- sélectionner les champs à importer;
- modifier le nom des champs;
- changer le type de données, s’il y a lieu;
- changer le type de stockage (servant à la production du schéma);
- basculer les principaux paramètres des champs uniques;
- établir si un champ peut avoir une valeur nulle.
Une fois les modifications terminées, cliquez le bouton « View Schema » pour passer à la dernière partie du processus, la migration des données.
4e étape : charger les données
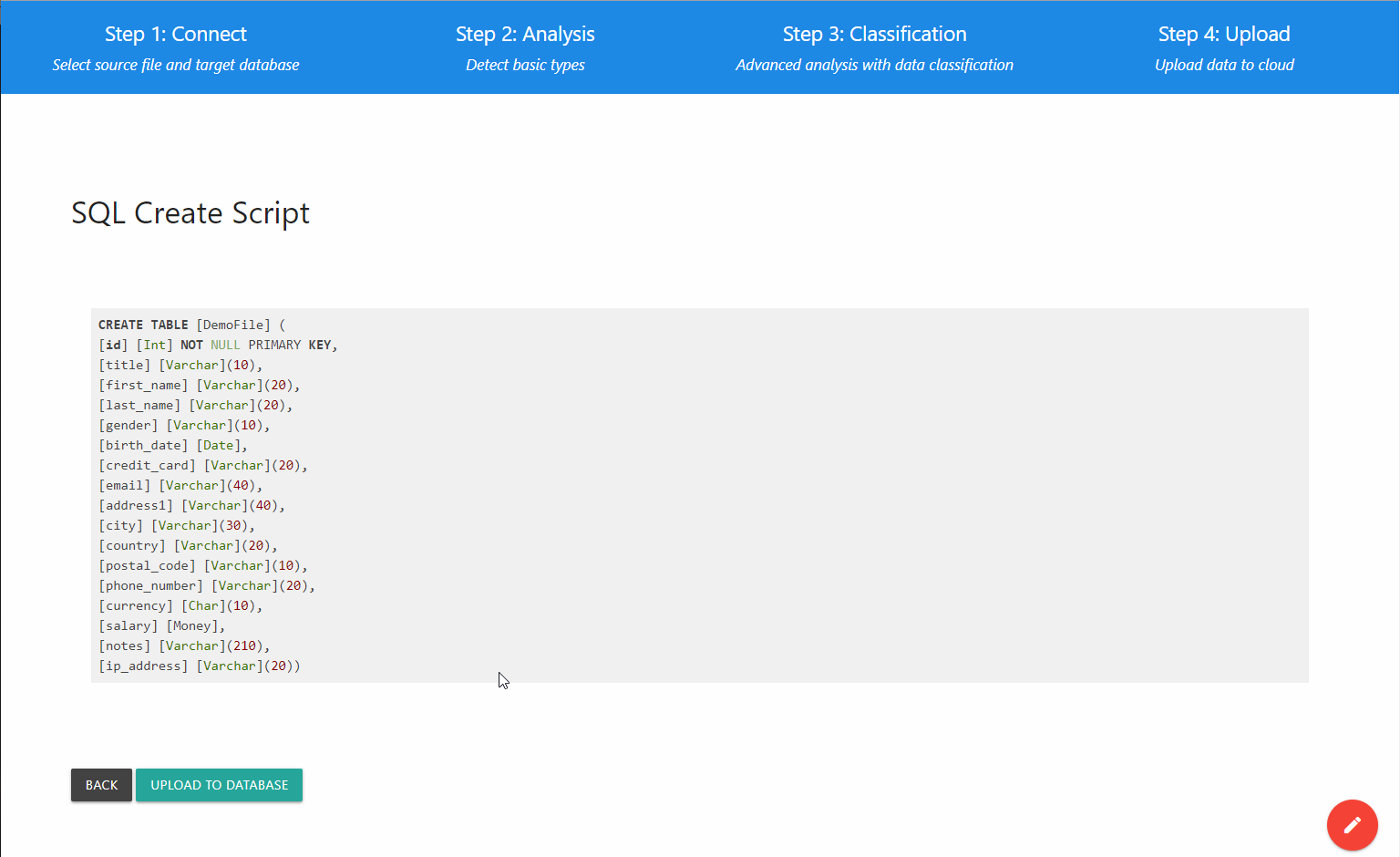
Clôture
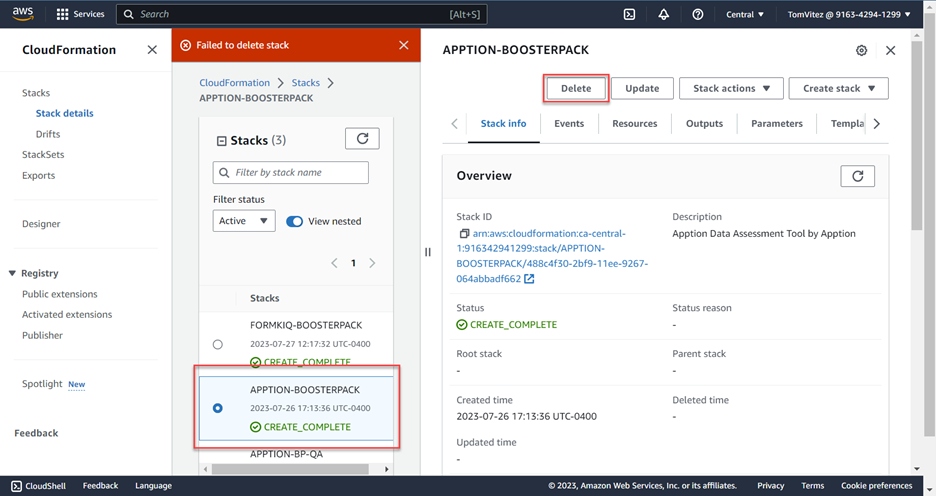
Après avoir franchi ces étapes et téléversé les données dans la base de données, vous pouvez arrêter l’application en fermant simplement l’onglet du navigateur. Pour libérer les ressources dans l’ATIR, vous devrez supprimer l’instance Pile et le(s) conteneur(s) que vous avez créé(s). Il est possible de le faire en une étape. Retournez à la page Piles de la console Cloudformation d’AWS, sélectionnez la pile à supprimer et cliquez « Supprimer ».