Introduction
La solution que propose ce Propulseur permettra à l’utilisateur d’observer et d’étudier comment l’apprentissage automatique résout le problème consistant à développer un modèle qui prévoit des séries chronologiques.
Ce document décrit la Solution type et les technologies sur lesquelles elle repose. Les participants de l’ATIR qui souhaitent apprendre comment appliquer l’apprentissage automatique aux réseaux neuronaux pourront s’en servir pour déterminer comment, quand et pourquoi adopter une telle approche lorsqu’ils élaborent leur solution.
La documentation s’appuie sur les solutions créées par BluWave-ai pour accélérer l’adoption des sources d’énergie propre par l’intelligence artificielle. Nos solutions de contrôle et d’opération, optimisées grâce aux prévisions, accroissent la rentabilité du nombre grandissant de réseaux intelligents et de micro-réseaux d’électricité recourant à des sources d’énergie renouvelable, au stockage d’énergie et à l’alimentation des véhicules électriques.
On trouvera la définition des expressions en italique dans le glossaire, à la fin du document.
Énoncé du problème
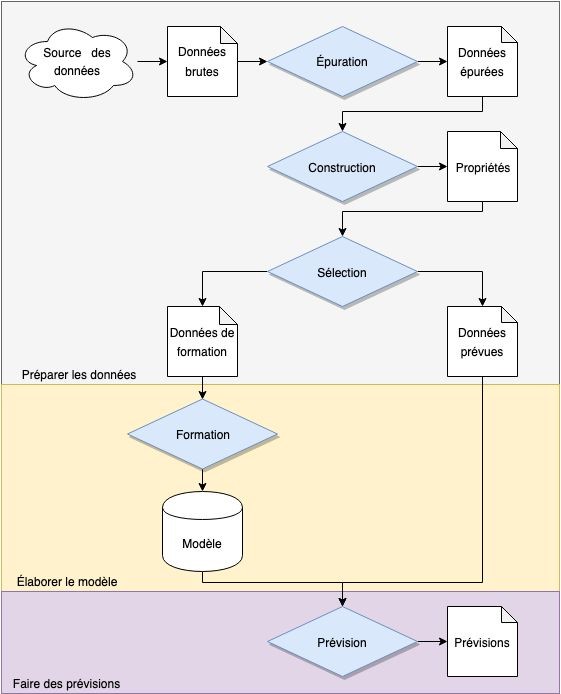
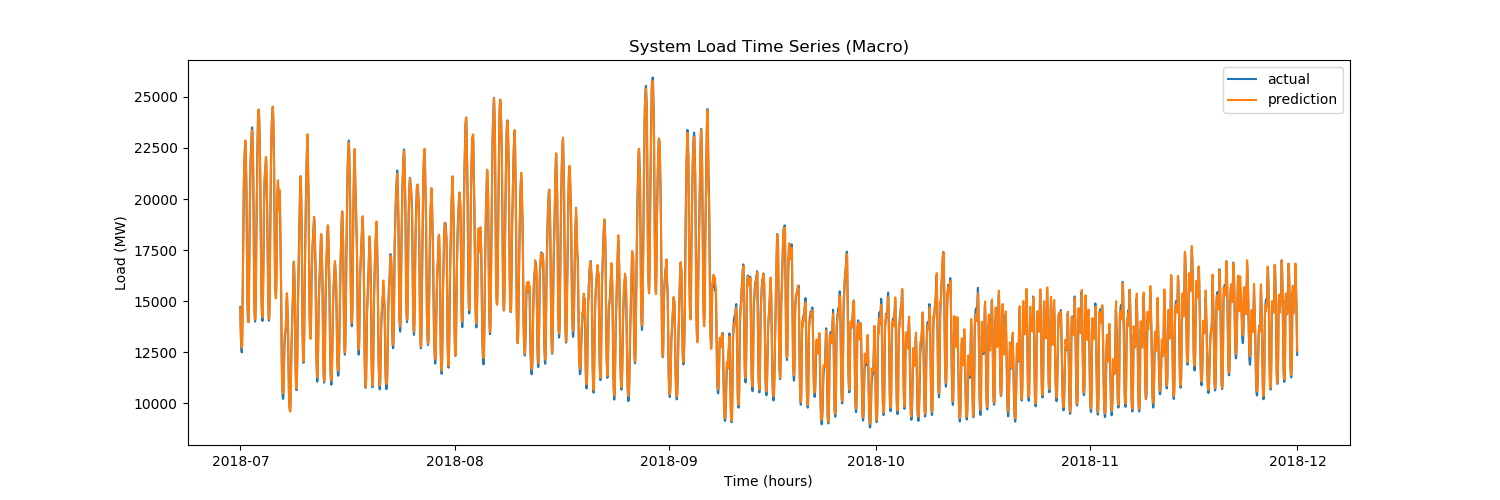
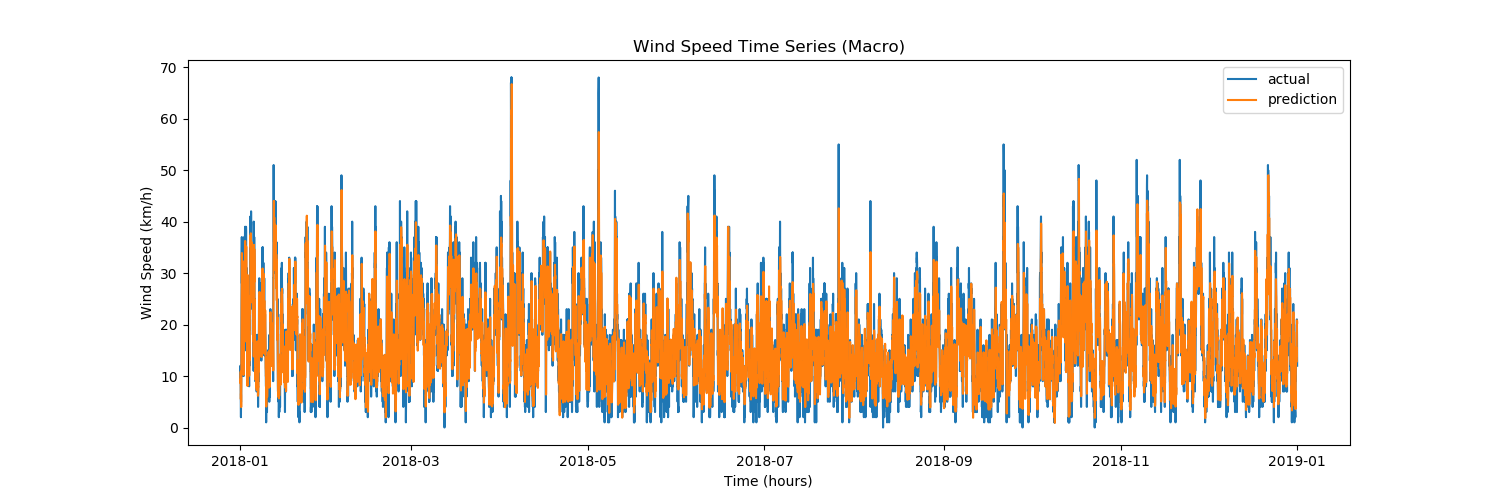
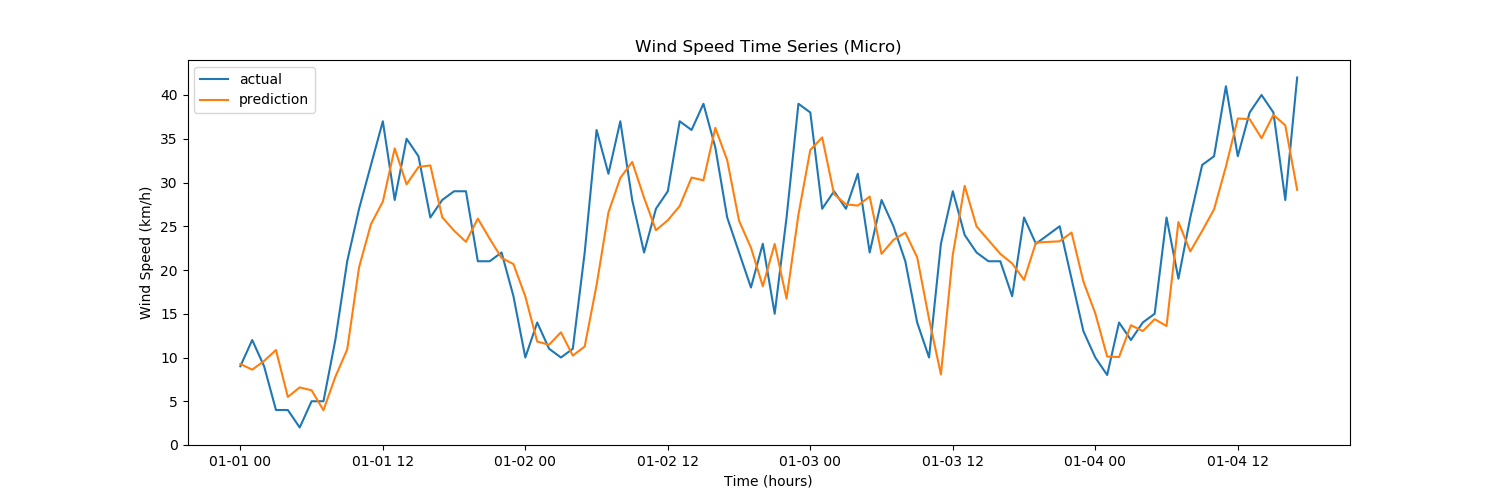
La prévision de séries chronologiques a pour objectif principal le développement de modèles qui produiront des valeurs futures plausibles en fonction des observations réalisées dans le passé grâce à la série chronologique qui en résulte et d’autres séries.
Une série chronologique est une suite de données prélevées à intervalles réguliers dans le temps. On y recourt souvent dans de nombreuses applications en statistique, finances, météorologie, sciences naturelles et génie. Prévoir une série chronologique autorise la prise de certaines mesures par anticipation, pour ajuster le comportement d’un système d’après un événement susceptible de se produire dans l’avenir. Les applications possibles ne manquent pas comme l’illustrent les exemples que voici.
- Optimisation de l’énergie : optimisation des réseaux intelligents par l’intelligence artificielle, surtout en présence de sources d’énergie renouvelable très variables et réparties comme l’énergie éolienne ou solaire.
- Villes intelligentes : régulation intelligente de la circulation, détection de problèmes de sécurité et envoi de patrouilles, optimisation des transports en temps réel.
- Sécurité des réseaux et des systèmes : détection et contrôle des intrusions.
- Gestion des infrastructures : détection des défaillances au moyen de capteurs, calendriers d’entretien préventif, optimisation des amortissements et des réparations.
- Logistique en temps réel : placement d’articles, location, optimisation du chargement et des expéditions.
- Médecine : prévision des futurs risques pour la santé ou du rétablissement d’après des données chronologiques sur l’état de santé.
Parmi les techniques de prévision classiques à base de séries chronologiques les plus connues, mentionnons l’usage de variables explicatives linéaires, l’accentuation des problèmes en l’absence d’un volume suffisant de données pour entraîner le modèle et les efforts déployés pour établir les propriétés de distribution des valeurs résiduelles en vue de l’application de tests statistiques. Ces méthodes ont toujours une grande utilité.
L’affinement de la théorie, la plus grande disponibilité des données, un meilleur arsenal de logiciels et l’exploitation de plus gros ordinateurs ont élargi le nombre de problèmes d’inférence pouvant être traités. Il en découle des avantages tangibles.
- Traitement de données plus volumineuses : il existe des périodes d’observation plus longues et on peut s’en servir avec des séries à chronologie parallèle pour prévoir l’exactitude des séries étudiées.
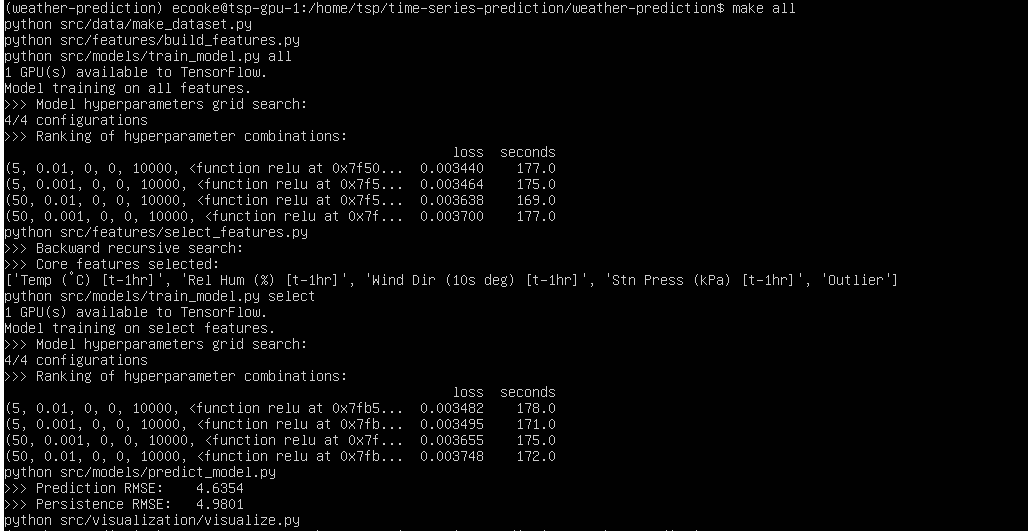
- Robuste traitement préalable des données : les techniques de pointe en apprentissage automatique peuvent traiter les données quasi brutes, alors que les modèle d’inférence statistique classiques peuvent réagir à des données historiques erronées, comme les valeurs aberrantes ou absentes. On le doit à l’utilisation d’éléments non linéaires plutôt que linéaires et, depuis peu, il est possible de valider des modèles complets entre eux.
- Apprentissage séquentiel : les modèles comme les réseaux neuronaux récurrents (RNR) ont suscité énormément d’intérêt pour la prévision des séries chronologiques, car ils ont un comportement dynamique dans le temps.
- Automatisation : les techniques d’apprentissage automatique peuvent être automatisées très efficacement, ce qui facilite un apprentissage continu et l’auto-amélioration.