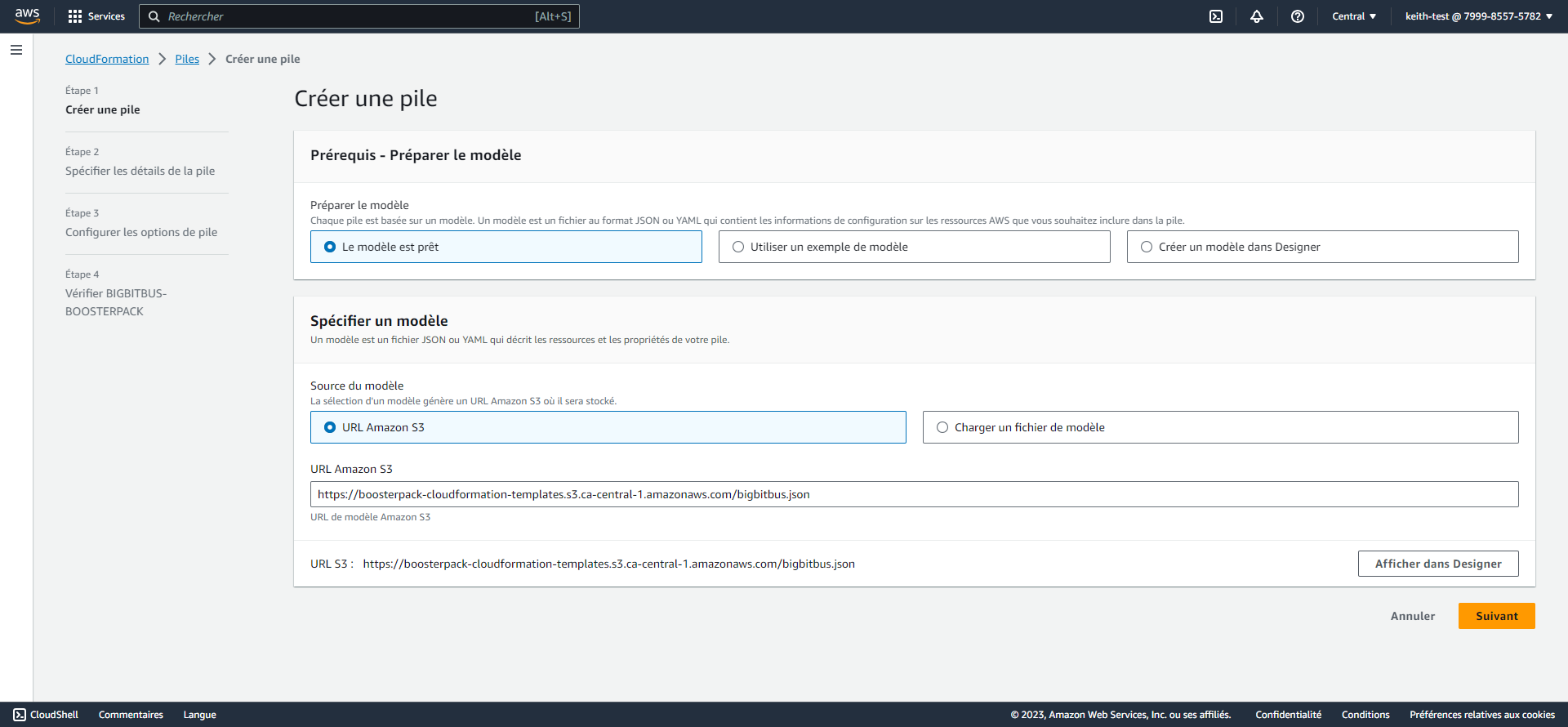
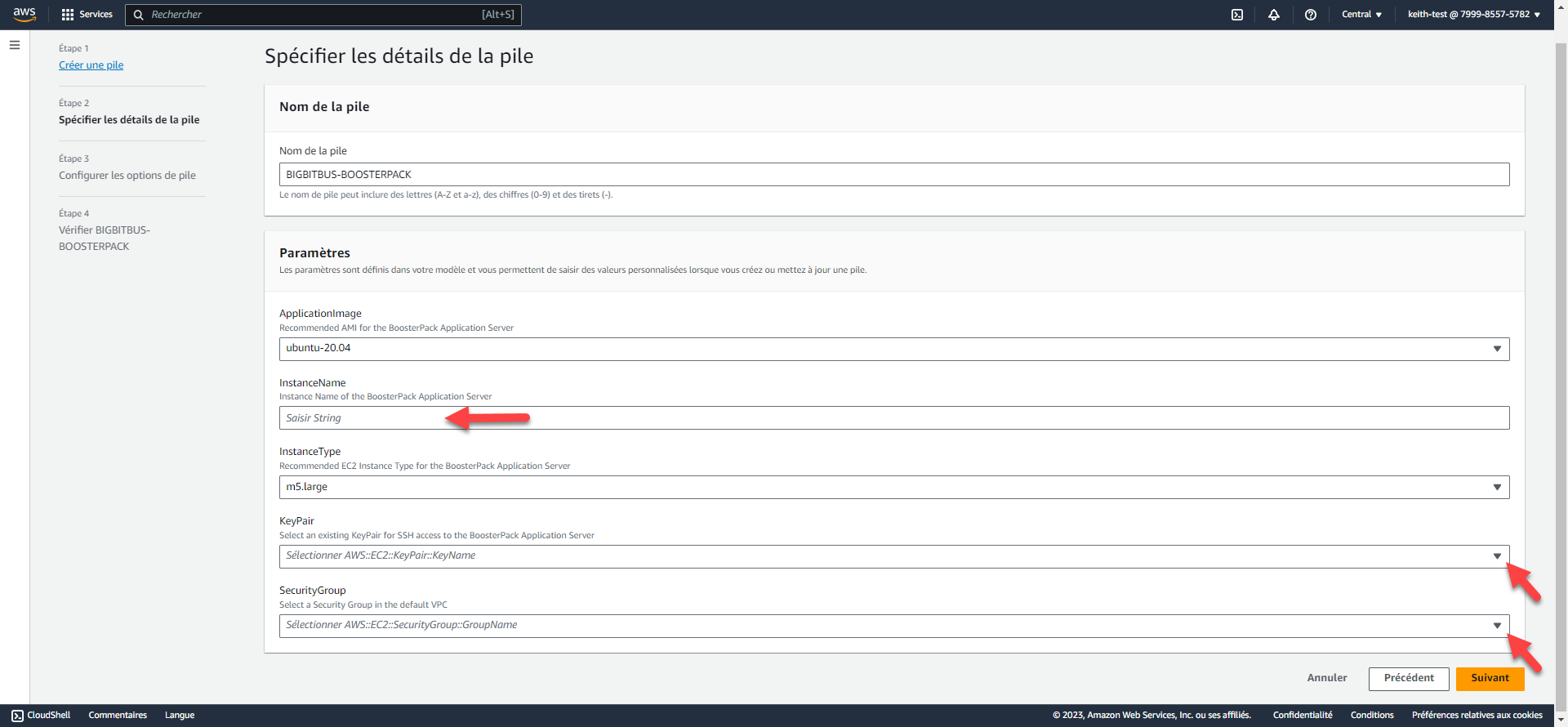
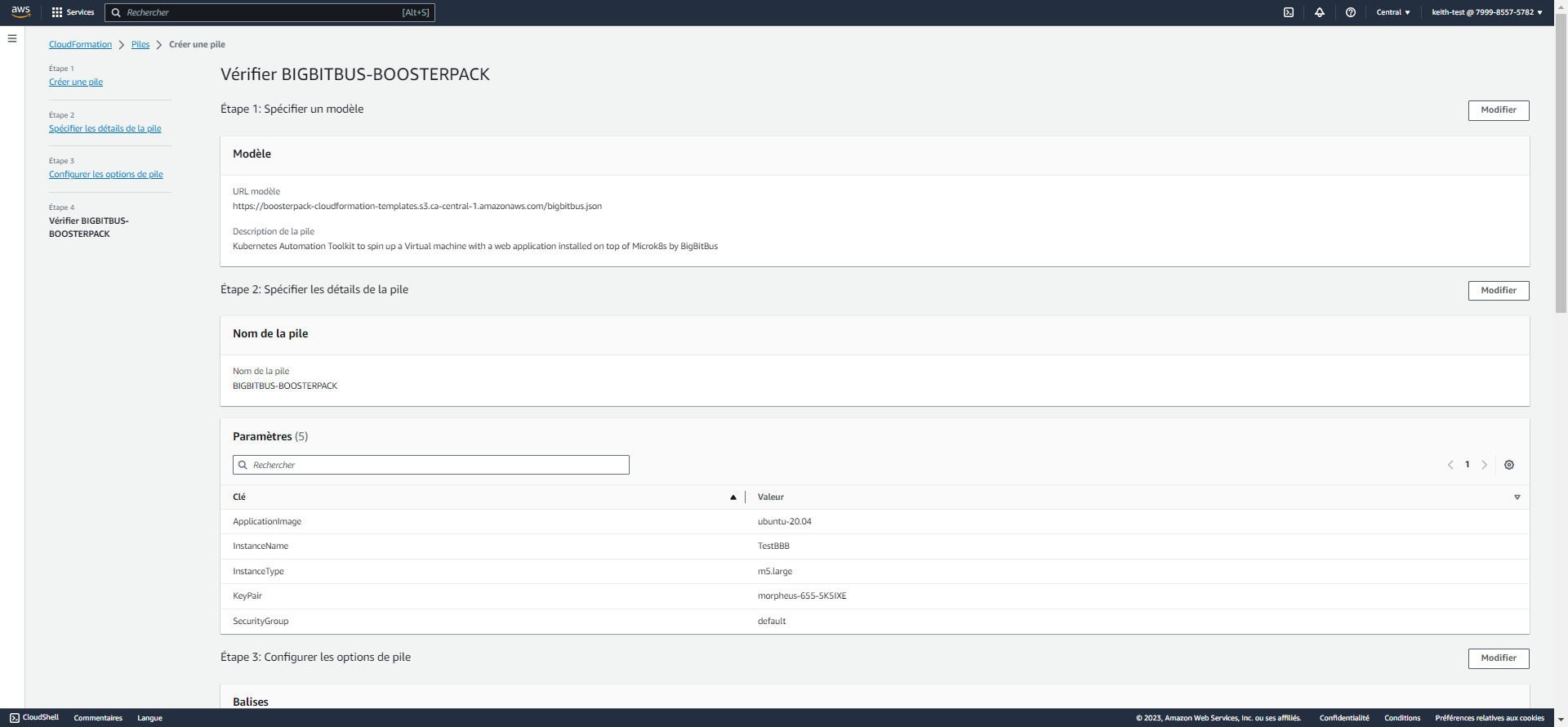
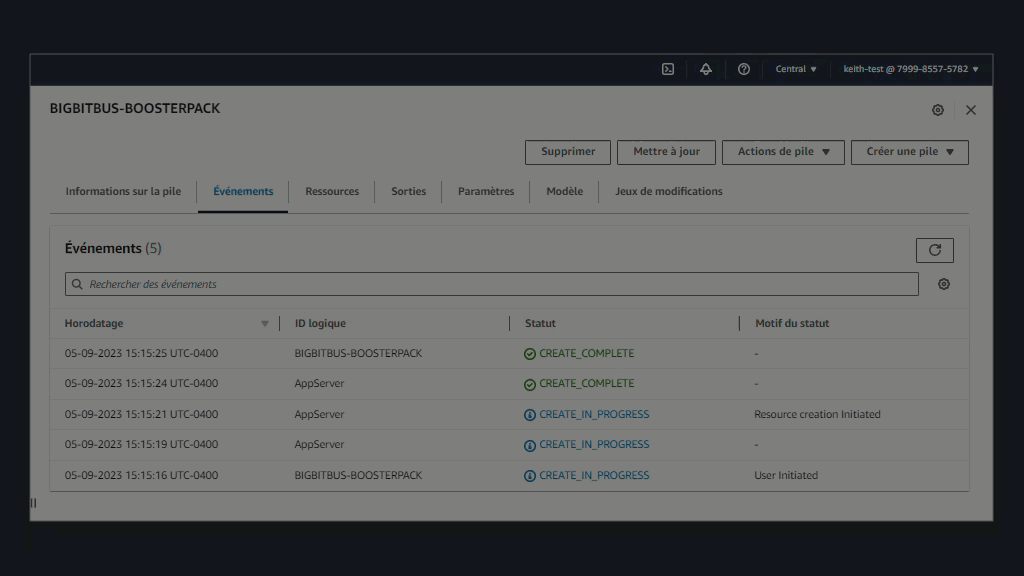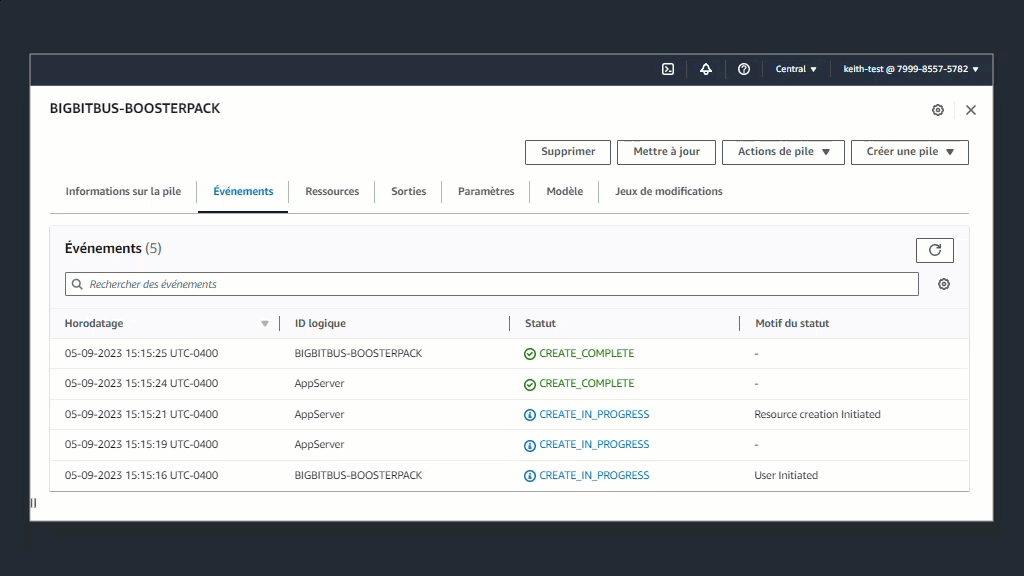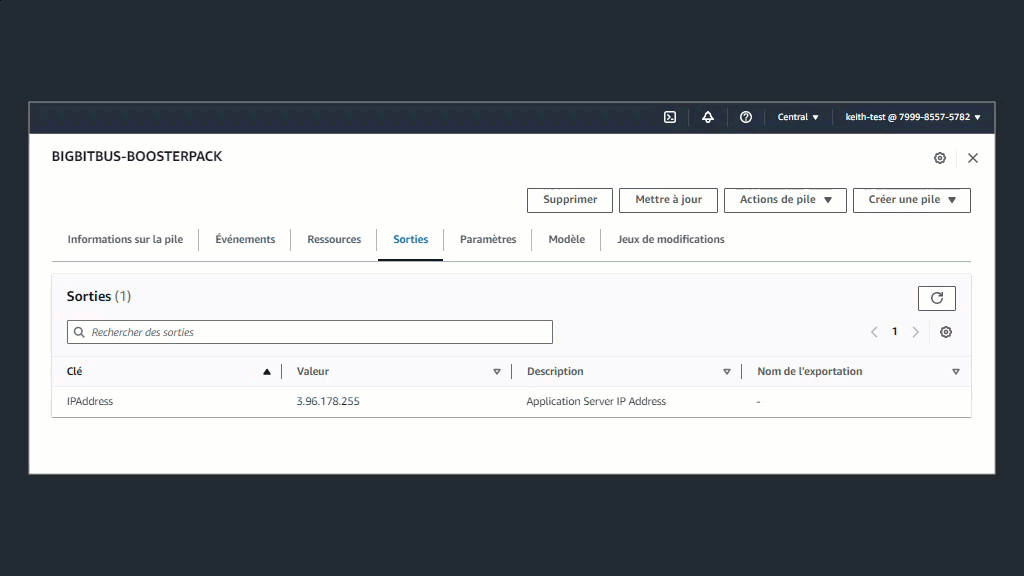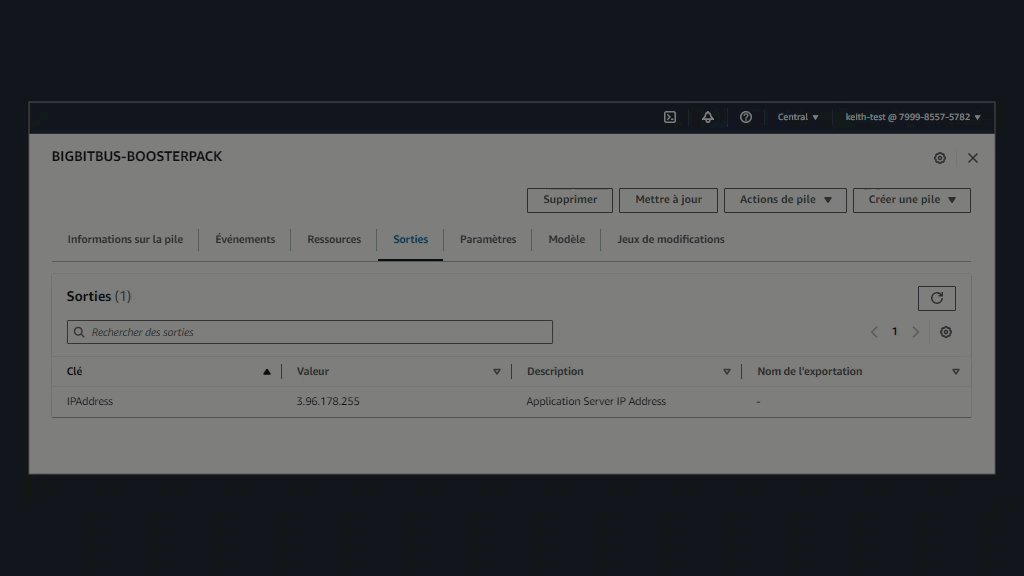
Considérations d’ordre technique
Les principales fonctionnalités de la solution type sont examinées ci-dessous. Nous vous recommandons vivement de prendre connaissance de la documentation la plus récente que vous trouverez dans le dépôt de source ouverte Kubernetes Automation Toolkit de BigBitBus à l’adresse :
https://GitHub.com/BigBitBusInc/kubernetes-automation-toolkit
Déploiement
Skaffold
Outil de construction automatique développé par Google pour les applications Kubernetes. Il gère le flux de tâches qui bâtit, initialise et déploie l’application. Grâce à lui, le développeur peut consacrer plus de temps au développement qu’à l’érection et au déploiement de son application. Les déploiements utilisant Skaffold reposent sur un fichier « skaffold.YAML » renfermant diverses informations comme l’image Docker à utiliser pour bâtir le conteneur, le chemin jusqu’à l’application, l’environnement dans lequel elle doit être déployée et ainsi de suite. En exécutant ce fichier, on laisse Skaffold surveiller un répertoire local d’applications pour y repérer les modifications et bâtir, initialiser et déployer une grappe Kubernetes locale ou éloignée dès qu’un changement a été décelé. Plus sur le sujet ici : https://skaffold.dev/docs/
Dans notre exemple, Skaffold nous permet de développer l’application dorsale Django et l’application frontale Vue.js sans avoir à en configurer le déploiement, comme le fichier des manifestes Kubernetes ou la reconstruction des images. Une exécution rapide de Skaffold bâtira l’application et la déploiera dans la grappe Kubernetes, avec surveillance des changements éventuels qu’on y apporte.
Helm
Gestionnaire de paquets de Kubernetes. Équivalent de Yum/Apt pour les applications Kubernetes. Helm crée et déploie des formules Helm (Charts), c’est-à-dire des paquets structurés sur l’architecture de Kubernetes. Ces formules confèrent une structure simple et normalisée aux manifestes Kubernetes nécessaires pour le déploiement. Après addition de la formule au dépôt Helm local, la commande rapide « Helm install [formule Helm] » simplifie le déploiement dans la grappe Kubernetes. Plus d’informations à ce sujet ici : https://helm.sh/docs/
Des formules Helm ont été créées pour les applications dorsale et frontale du Propulseur, en conformité avec la structure déjà employée pour les autres composants. On s’est aussi servi de Helm pour installer la base de données PostgreSQL de Bitnami, l’opérateur Prometheus et Grafana.
Modules surveillant les activités dans la grappe Kubernetes. Développé par SoundCloud, Prometheus se veut une solution complète pour visualiser et journaliser les données transférées dans la grappe. Ses principales fonctionnalités comprennent des modèles de données évolués pour les ressources de Kubernetes, un langage de recherche polyvalent et de nombreux types de graphes et de tableaux de bord. Grafana est un logiciel de visualisation permettant à l’utilisateur de mieux saisir ce qui se passe dans la grappe Kubernetes. Grafana restitue les données sous forme de graphes, de formules, de mesures et de cartes, ce qui simplifie la supervision d’une grappe complexe.
Grafana est doté d’un soutien intégré pour les recherches sur Prometheus. Le logiciel récupère les données glanées par Prometheus et les affiche de manière structurée grâce à une interface graphique au moyen de laquelle l’utilisateur peut suivre l’activité des ressources dans un espace de nommage donné de la grappe.
Applications
Vue.js (application frontale)
Cadriciel ouvert en JavaScript servant à bâtir des interfaces utilisateur. Il intègre le côté réactif de la conception Web permettant de connecter la partie en JavaScript au code HTML. Quand les données du composant en JavaScript changent, l’interface (HTML/CSS) se reconfigure automatiquement.
Dans notre Propulseur, l’application Vue.js fonctionne sous la forme d’une application frontale d’une page, c’est-à-dire une interface graphique avec laquelle l’utilisateur lance les appels RESTful habituels à l’application dorsale sans avoir à interagir directement avec elle.
Pour les invites de l’API, l’application recourt à un outil baptisé « Axios » de la bibliothèque JavaScript. Cet outil configure la requête en format HTTP de base avant de l’expédier au serveur dorsal.
| Méthode |
Description |
| OBTENIR (GET) |
Au chargement de la page, l’application exécute automatiquement une commande qui récupère les choses de la liste (todos) qui n’ont pas encore été faites dans la base de données. |
| AFFICHER (POST) |
Encadré demandant à l’utilisateur ce qu’il y a « à faire » pour l’inciter à ajouter des choses à la liste. |
| MODIFIER (PUT) |
En double-cliquant une chose à faire, l’utilisateur peut la modifier. La touche ÉCHAP annule la modification. |
| SUPPRIMER (DELETE) |
En survolant les choses encore à faire avec la souris et en cliquant le « x » rouge, on supprimera la chose en question de la liste. |
Le CSS utilisé pour exécuter l’application est dérivé du modèle suivant :
https://GitHub.com/Klerith/TODO-CSS-Template
Pour accéder au répertoire dans lequel figurent les fichiers Vue.js, suivre le chemin :
https://GitHub.com/BigBitBusInc/kubernetes-automation-toolkit/tree/main/code/app-code/frontend/ToDo-vuejs
Le code sous-jacent présenté à l’utilisateur figure plus loin dans src/App.vue. Ne sont présentés ici que les composants HTML/CSS de base portant l’étiquette <template> et les composants JavaScript portant l’étiquette <script>.
Pour en savoir plus sur Vue.js, aller à : Introduction — Vue.js
Django (application dorsale)
Cadriciel Web ouvert en Python établissant les composants de base d’un projet en vue d’une application Web. Ainsi, l’utilisateur peut consacrer plus de temps au développement et moins au déploiement. La syntaxe est facile à saisir et comprend l’architecture de base d’un serveur Web.
Dans notre Propulseur, l’application Django fait office d’application dorsale qui établit l’API todos. Elle prend en charge les appels de l’API et envoie ou récupère l’information dans la base de données.
Au démarrage, l’application crée une liste « todo » modèle avec pour attributs, notamment, le titre et la description d’une chose à faire (todo), principal objet sur lequel repose l’application. Celle-ci établit une connexion avec la base de données et y envoie l’information du modèle par migration. Ensuite, la base de données produit un tableau présentant l’ensemble des objets todo.
Avec comme routeur le « DefaultRouter » de Django, l’application cartographie automatiquement les requêtes HTTP de l’application frontale en regard du jeu d’objets todo grâce à un ensemble « Viewset ». « Viewset » utilise des opérations comme énumérer, créer, actualiser et supprimer qui modifient le contenu de la base de données chaque fois que les objets changent. Par exemple, quand on ajoute un objet todo avec l’application Vue.js, le routeur saisit la requête, la cartographie selon sa méthode et l’expédie dans « Viewset », qui la prend en charge par l’opération « créer » du modèle. Quand la liste d’objets todo est modifiée, l’application Vue.js réagit en actualisant la page.
Le code de l’API todos a été dérivé de l’original, disponible à l’adresse : GitHub – wsvincent/drf-todo-api: Django REST Framework Todo API Tutorial
Pour voir le répertoire groupant tous les fichiers de code Django, on suivra le chemin kubernetes-automation-toolkit/code/app-code/api/todo-python-django at main · BigBitBusInc/kubernetes-automation-toolkit · GitHub
Pour en savoir plus sur le cadriciel REST de Django, lire : https://docs.djangoproject.com/fr/3.1/
Autres considérations
Sécurité
La MV de l’ATIR sur laquelle fonctionne la grappe Kubernetes hébergeant l’application todos n’est accessible que sur le port 22 (SSH). Pour explorer l’application et les points terminaux de Grafana, nous recourons à une tunnellisation sécurisée entre l’ordinateur et la MV. Les rustines de sécurité sont automatiquement appliquées à la MV d’Ubuntu par le modèle de l’application (Application Blueprint).
Les formules Helm (Charts) de l’échantillon comprennent des blocs de code TLS/SSL commentés qu’il est possible d’activer avec un certificat TLS valable pour le domaine. En réalité, on ne se connecterait pas avec un tunnel SSH, mais par encryptage TLS en utilisant le protocole sécurisé HTTPS. Les fichiers « values.YAML » comprennent des parties non commentées, ce qui vous permettra d’utiliser vos propres certificats SSL quand viendra le moment de déployer l’application afin que des utilisateurs de l’extérieur puissent s’en servir. Pour en savoir plus sur le fonctionnement de la couche TLS et des composants d’entrée, lisez ceci.
Dans la solution modèle KAT, nous avons attribué les justificatifs de l’administrateur de Kubernetes (root-admin) à l’utilisateur de la MV. En fait, comme c’est le cas pour n’importe quelle grappe de production dans laquelle de multiples utilisateurs ou services ont accès à Kubernetes, l’idéal consiste à utiliser le contrôle des accès basé sur les rôles. Nous vous encourageons à examiner les nombreux aspects associés à la sécurité avant d’utiliser Kubernetes dans un environnement de production.
Nous nous sommes servis de la fonction « secrets » de Kubernetes (pour stocker le mot de passe Postgres, par exemple, et l’appliquer à la formule Helm); nous préconisons l’usage de cette fonction plutôt que de configmaps en texte clair quand Kubernetes stocke des données sensibles.
Voici quelques excellentes ressources pour vous aider à démarrer si vous voulez en apprendre davantage sur la sécurité et Kubernetes.
-
- Documentation officielle de Kubernetes sur la sécurisation des grappes : https://kubernetes.io/docs/concepts/security/
- Gestion automatique des certificats avec Cert-Manager en cloud-native : https://cert-manager.io/
Réseau
Comme nous l’avons déjà mentionné, les composants d’entrée NGINX servent à rendre les points terminaux de l’application visibles au monde extérieur. Après avoir créé la MV dans l’ATIR, creusez un tunnel SSH entre le port local 8080 et le port HTTP 80 de la MV.
Cela fait, l’utilisateur pourra accéder aux composants de l’application avec le navigateur de son ordinateur aux endroits indiqués. Attention : le trait oblique final est obligatoire!
Points terminaux (après connexion à l’hôte local 8080 par le tunnel SSH)
| Application frontale todos |
http://localhost:8080/frontend/ |
| API dorsale |
http://localhost:8080/djangoapi/ |
| Système de surveillance Grafana |
http://localhost:8080/monitoring-grafana/ |
| Tableau de bord Kubernetes |
http://localhost:8080/dashboard/ |
La solution type KAT utilise Ingress Controller de NGINX, ce qui ouvre une foule de possibilités pour configurer les demandes de routage et de réseautage de la couche 7. Le serveur NGINX fait office de serveur de procuration inversé et d’équilibreur de charge. NGINX est extrêmement polyvalent et propose de nombreuses options pour configurer le trafic.
Apprenez en plus sur NGINX Ingress de Kubernetes ici.
Mise à l’échelle
Les fichiers « values.YAML » dans les formules Helm des applications frontale et dorsale ont un paramètre appelé « replicas » qui peut être modifié en fonction du nombre de répliques. L’Horizontal Pod Autoscaler de Kubernetes est également activé, si bien que le nombre de répliques s’ajuste automatiquement en fonction de l’utilisation de l’UCT par les Pods. Voir les fichiers « values.YAML » dans les formules Helm pour comprendre comment ces paramètres sont configurés. N’hésitez pas à expérimenter en fixant le nombre de répliques dans chaque fichier values.YAML employé pour le déploiement.
Disponibilité
Kubernetes peut créer de nombreux Pods qui utiliseront le même logiciel (l’application dorsale de Django ou l’application frontale Vue.js, par exemple). L’application est donc très facilement accessible. Cette particularité revêt une importance particulière quand on recourt à une grappe Kubernetes à nœuds multiples. Par exemple, si on l’exécute dans une grappe de ce genre, l’application todos restera active même si un nœud défaille. Kubernetes détectera puis relancera automatiquement le nœud défectueux. L’utilisateur ne s’en rendra pas compte, ce qui simplifie considérablement le travail technique requis quand on doit exploiter et maintenir des applications sur une plateforme de production d’une grande accessibilité.
Coût
Habituellement, la taille de la grappe Kubernetes est proportionnelle au nombre de nœuds d’exécution qu’elle abrite. Dans la solution type KAT, nous nous contentons d’une grappe à un nœud sur une seule machine virtuelle, mais les nœuds d’exécution et de contrôle seront plus nombreux dans la réalité, et les frais de réseau de même que ceux d’équilibrage de la charge pourraient s’accroître sensiblement avec l’expansion de la grappe. Pour avoir une idée du coût « réel » d’une grappe Kubernetes, nous vous suggérons de recourir à la calculatrice d’un des nuages publics, par exemple :
Google : https://cloud.google.com/products/calculator
Amazon AWS : https://calculator.aws/#/
Microsoft Azure : https://azure.microsoft.com/en-us/pricing/calculator/
Licence d’exploitation
Tous les composants de la solution type KAT sont visés par une licence de source ouverte; veuillez vous rapporter au dépôt de la source correspondante pour en savoir plus sur les conditions qui s’y associent. La licence pour le code du Propulseur KAT et la documentation connexe sont disponibles ici :
https://GitHub.com/BigBitBusInc/kubernetes-automation-toolkit/blob/main/LICENSE.md
Code source
On trouvera le code source à jour ici :
https://GitHub.com/BigBitBusInc/kubernetes-automation-toolkit
Glossaire
Termes et expressions utilisés dans le document.
| Expression |
Description |
Lien/Complément d’information |
| Django |
Cadriciel Web gratuit de source ouverte en Python |
|
| Helm |
Gestionnaire de paquets pour Kubernetes |
|
| Kubernetes |
Système d’orchestration de conteneurs ouvert automatisant le déploiement, la mise à l’échelle et la gestion d’une application |
|
| Microk8s |
Système de distribution Kubernetes allégé, prêt à l’emploi |
|
| PostgresSQL |
Système de gestion ouvert pour les bases de données relationnelles |
|
| Prometheus et Grafana |
Base de données chronologiques et système de recherche de données avec interface utilisateur |
|
| Skaffold |
A build and deploy tool for Kubernetes |
|
| Vue.js |
Illustration d’un fichier de définition Skaffold en YAML |
|