
Pipeline de données automatisé (ADP)
Voici ce que vous trouverez dans cet solution type :
Introduction
Dans cette solution, nous vous montrerons comment Intelius Analytics s’est servi de Kubernetes, d’Airflow d’Apache, de MySQL, de FastAPI, de Kafka d’Apache et de React.js pour automatiser deux pipelines de données en créant un cadre intégré à partir de ressources ouvertes.
Énoncé du problème
Trouver un cadre peu coûteux qui automatisera un pipeline de données dans son intégralité et qu’on pourra adapter aux multiples besoins d’une entreprise n’est pas aisé. Une architecture à trois ou quatre paliers règlera la plupart des problèmes de données de l’entreprise. Toutefois, il est difficile de dénicher un produit de base ou un prototype à partir desquels on pourra structurer des microservices.
Le plus souvent, l’organisation embauchera des architectes (spécialisés dans les données ou les entreprises) pour concevoir et développer une architecture, puis confiera l’élaboration des services indépendamment à une équipe de développement (regroupant des compétences précises). Créer une architecture de base demande en soi plusieurs mois et l’organisation dépensera des milliers de dollars en personnel pour amorcer le travail quand on doit partir de zéro. La solution que voici servira de point de départ et évitera à l’organisation de bâtir un pipeline de données automatisé de A à Z.
Bien que la solution proposée automatise l’ingestion, le traitement, le stockage et la présentation des données et des informations boursières, on pourra s’en servir comme approche générale aux problèmes les plus fréquents dans une entreprise. La majorité des pipelines automatisés sont conçus de la même façon pour gérer les données. L’organisation aura donc une longueur d’avance et n’aura qu’à adapter la solution selon les besoins qui lui sont propres.
Applications potentielles
- Analyse des données venant de l’Internet des objets (IdO) dans diverses industries : des données issues de capteurs aux déductions, ce Propulseur servira de fondation au calcul informatisé en périphérie de réseau et au traitement des données en arrière-plan
- Traitement robotisé des données en temps réel et intégration aux activités effectuées en arrière-plan
- La détection des fraudes, la formulation de recommandations en temps réel et l’analyse assistée par la voix (assistant personnel) figurent parmi les applications possibles de l’architecture proposée pour les microservices
N’importe quelle entreprise qui souhaite instaurer un service d’analyse en temps réel ou quasi-réel tirera parti de cette architecture qui n’est assujettie à aucun nuage commercial.
Pipelines de données automatisés (ADP) dans le nuage de l’ATIR – Solution type
Diagramme
Voici une illustration de la solution type sous forme de diagramme.

Éléments
Le tableau qui suit résume les principaux éléments dont est constituée la Solution type. Le Plan de vol donne un aperçu des technologies et des outils qu’elle emploie et qui apparaissent dans le diagramme ci-dessus (Kubernetes, Airflow et Kafka d’Apache, FastAPI, MySQL).
| Composant | Description |
|---|---|
| Service d’ingestion | Service créé en Python pouvant être déployé indépendamment et au moyen duquel les données venant de l’extérieur sont ingérées puis acheminées au service de messagerie Kafka. La Solution type compte deux pipelines de graphes orientés acycliques (GOA) sur une instance Airflow pour l’ingestion des données : 1) le premier saisit le cours boursier toutes les minutes, pendant les heures d’ouverture normales de la bourse [de 9 h 30 à 16 h, HE]; 2) le second saisit les informations du téléscripteur sur cinq titres cotés en bourse aux États-Unis [AAL, AAPL, AMD, MSFT et TSLA] toutes les cinq minutes. Le cours de la bourse est ingéré à partir d’une API gratuite de Finnhib.io et les informations boursières, au moyen d’une API pour téléscripteur gratuite de Polygon.io. |
| Service de traitement | Service déployable indépendamment, créé en Python, qui traite les données ingérées à l’étape précédente. Il permet à l’utilisateur de traiter les données plus en profondeur par en ajoutant de nouvelles fonctionnalités comme leur adaptation à un nouveau schéma, leur épuration, leur configuration et leur intégration aux données d’autres sources. Deux pipelines sur la même instance Airflow ingèrent les données à traiter, c’est-à-dire : 1. le cours de la bourse sous forme de messages Kafka; 2. les informations boursières sauvegardées dans une table de la base de données MySQL. Dans le premier pipeline, l’indicateur technique EMA9 [moyenne mobile exponentielle de neuf jours] est calculé puis enregistré dans la base de données MySQL pour illustrer une procédure de traitement typique. Dans le deuxième, les informations sont envoyées à une API qui prédit le sentiment suscité par l’information et la prévision est stockée dans la base de données MySQL. |
| Service d’analyse | Service créé en Python et déployable seul, permettant l’élaboration de modèles d’analyse simples ou complexes, en vertu de l’usage qu’on souhaite en faire. La Solution type utilise un modèle de prévision des sentiments préformé pour prédire quelle influence (positive, neutre ou négative) chaque information ingérée aura sur le titre suivi par le téléscripteur. La nature du sentiment est définie d’après la note qu’attribue le modèle de traitement en langage naturel (NLP). La fonction prévisionnelle s’exprime sous la forme d’une API créée par un outil FastAPI, que convoque le pipeline de traitement des informations boursières. |
| Service de données | La Solution type utilise MySQL comme outil de source ouverte pour stocker les données. Par défaut, elle crée une base de données appelée « pipelines de données automatisés » et comprenant trois tables lors de son déploiement. La Solution type recourt aussi à la plateforme de messagerie de source ouverte Kafka d’Apache pour enregistrer les données à chaud (comme cela se fait habituellement avec la diffusion en continu à faible latence). Ce service crée le sujet « DAIR-dataingestion-1min-topic », qui correspond au cours de la bourse que le téléscripteur actualise toutes les minutes. |
| Service intermédiaire (en arrière-plan) | Les résultats du système sont récupérés avec les API de ce service, qui correspond à la couche séparant celles de traitement et de présentation des données. La Solution type crée deux API donnant accès aux données et aux informations boursières traitées avec FastAPI. Bien que ces API soient normalement convoquées par les services clients, on peut y accéder avec l’interface utilisateur Swagger ou Redoc. Pour en savoir plus à ce sujet, lisez cette page de la documentation sur FastAPI. |
| Service client (présentation des données) | Ce service établit une interface avec laquelle l’utilisateur accède aux résultats du système. L’application dans cette couche pourrait correspondre à un tableau de bord, à des pages Web, à une application mobile ou à d’autres outils frontaux. La Solution type déploie une page Web sur laquelle apparaissent le cours du titre coté en bourse sous forme de graphique en chandelier et les plus récentes informations boursières, dont le sentiment prévu, une fois qu’on a choisi un titre et une date. La page a été développée avec la technologie React.js. |
| Kafdrop | Kafdrop est une interface utilisateur de source ouverte permettant de voir les courtiers, les sujets, les consommateurs et les producteurs de Kafka, ainsi que de parcourir les messages de Kafka. |
Déploiement et configuration
Si vous êtes inscrit à l’ATIR, la Solution type peut être déployée sur une nouvelle instance pour vue que les instructions qui suivent soient respectées.
À vérifier avant le déploiement
La Solution type s’appuie sur le Propulseur « Trousse d’automatisation Kubernetes » (KAT), qui repose sur les hypothèses ou les prérequis que voici :
- vous avez créé un groupe de sécurité donnant accès aux machines virtuelles (MV) établies dans le nuage de l’ATIR par SSH, à leur adresse IP (TCP port 22);
- vous avez configuré une clé SSH privée pour accéder aux MV de l’ATIR;
Vous devez pouvoir créer une MV Linux dans le nuage de l’ATIR et vous y connecter par SSH avant de continuer.
Attention : Le Propulseur KAT n’a pas besoin d’être installé avant le Propulseur ADP, car celui-ci intègre le script nécessaire pour créer un nœud microK8 de Kubernetes et installer les outils pertinents, comme le tableau de bord Kubernetes, le contrôleur d’entrée NGINX et le gestionnaire de paquets Helm.
Obtenez les clés des API de Finnhub.io et Polygon.io
Pour ingérer les cotes et les informations boursières en temps réel, inscrivez-vous gratuitement aux services finnhub.io et polygon.io. Ces deux organisations proposent un abonnement gratuit qui vous permettra d’obtenir le cours des titres cotés en bourse et les informations pertinentes (des limites s’appliquent) dont le Propulseur aura besoin. La Solution type est conçue pour fonctionner normalement avec le nombre restreint d’appels lancés par l’API en vertu de ces abonnements gratuits.
Une fois inscrit, copiez les clés de l’API (jeton) qui correspond à chaque source de données. Vous en aurez besoin lors du déploiement de la Solution type.
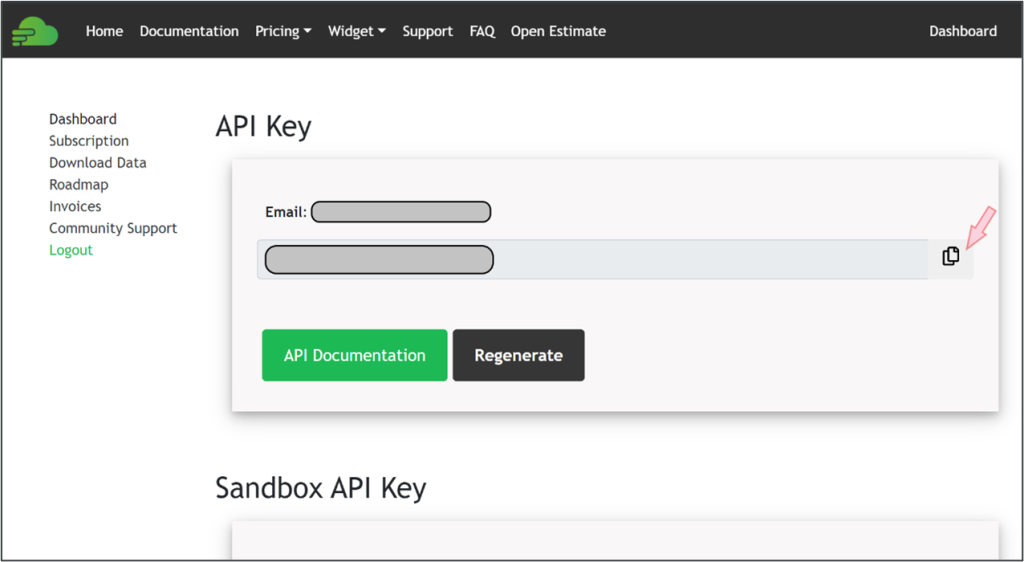
Dans le cas de finnhub.io, après vous être connecté, vous trouverez la clé gratuite et pourrez la copier sur le tableau de bord principal, comme le montre l’illustration ci-dessous.
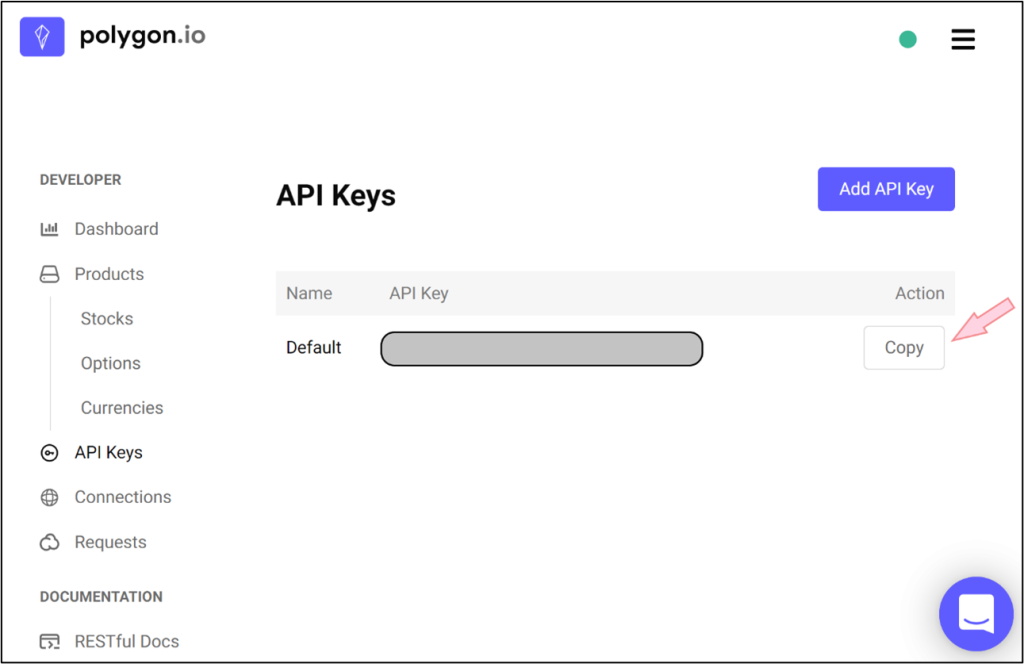
Pour polygon.io, après l’inscription, vous devrez vous rendre à la page API Keys et cliquer Add API Key. Ensuite, il vous suffira de copier la clé gratuite de la manière indiquée ci-dessous.
Déploiement de la Solution type dans le nuage de l’ATIR
Connectez-vous à votre compte AWS de l’ATIR en suivant les instructions que vous a fournies l’équipe de l’ATIR.
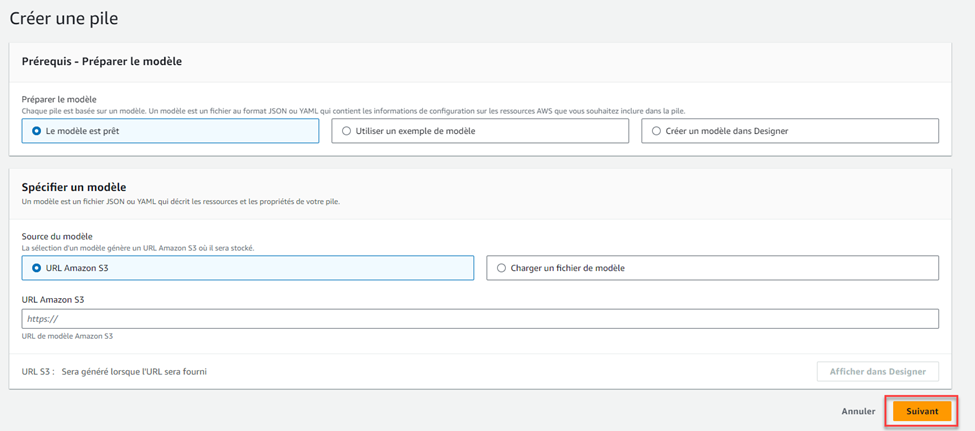
Ouvrez une autre fenêtre dans le navigateur et allez à la page du Catalogue des Propulseurs de l’ATIR puis à la section d’Intelius (Pipeline de données automatisé) et cliquez DÉPLOYER pour lancer le Propulseur avec la pile AWS Cloudformation.
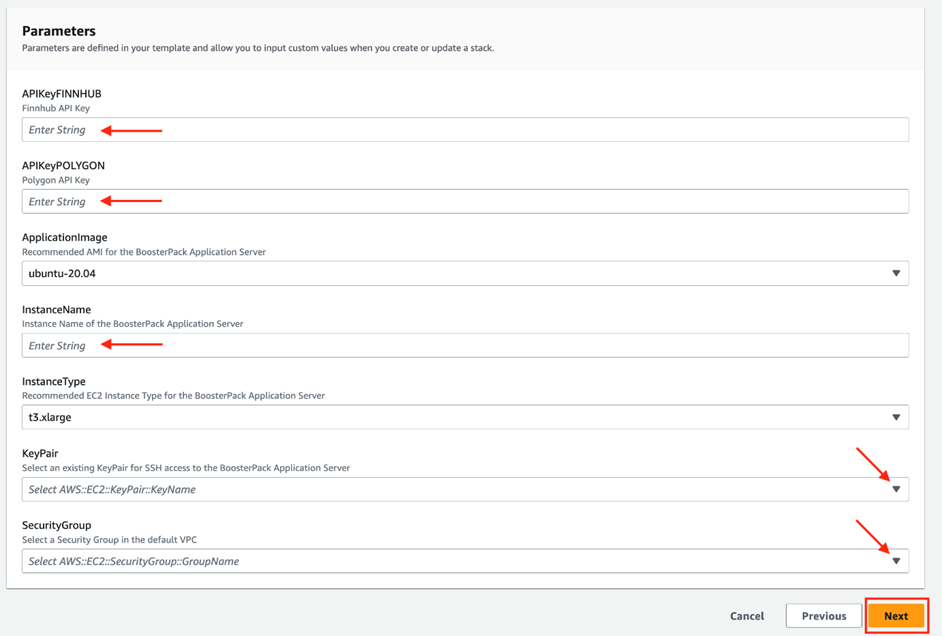
Cliquez Suivant pour passer à la deuxième étape de Cloudformation et remplissez le formulaire de configuration. Dans les champs APIKeyFINNHUB et APIKeyPOLYGON, respectivement, saisissez les clés de l’API que vous avez copiées après vous être inscrit gratuitement sur Finnhub.io et polygon.io. Dans le champ InstanceName, donnez un nom unique à une instance de votre serveur d’application, puis complétez le formulaire avec les menus déroulants. Veuillez noter que certains paramètres comme ApplicationImage et InstanceType sont déjà configurés et ne peuvent être modifiés.
Cliquez SUIVANT pour passer à la troisième étape de CloudFormation. Cette partie concerne la configuration d’options avancées ou supplémentaires, inutiles dans le cas qui nous intéresse. Cliquez simplement Suivant au bas de la page pour sauter cette étape et passer à la quatrième et dernière de CloudFormation.
La dernière partie vous permet de vérifier la configuration actuelle du Propulseur et d’y apporter des modifications avec le bouton Modifier, si vous le désirez. Une fois que la configuration vous convient, cliquez Soumettre, au bas de la page, pour déployer le Propulseur.
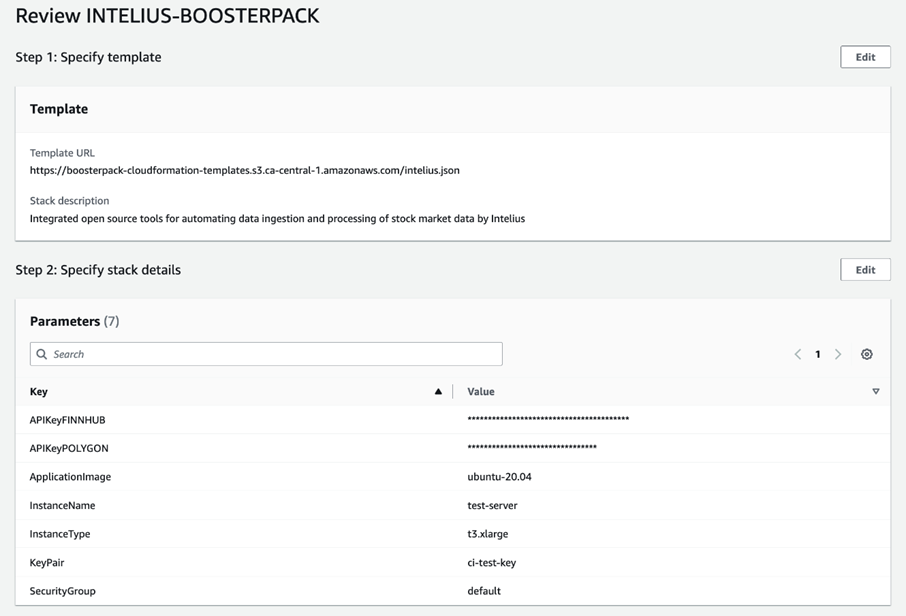
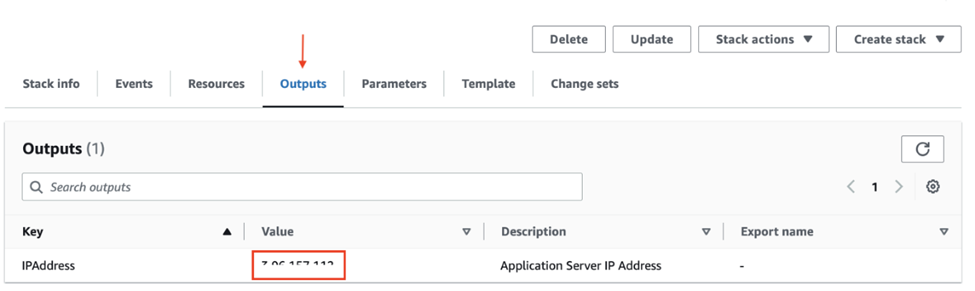
Le déploiement commence par la création d’une nouvelle instance. Le reste est automatique. Suivre le développement de l’instance AWS n’est possible qu’avec les onglets Événements et Ressources de la console CloudFormation. Pour vérifier l’avancement du déploiement, vous devrez donc vous connecter au serveur de l’application.
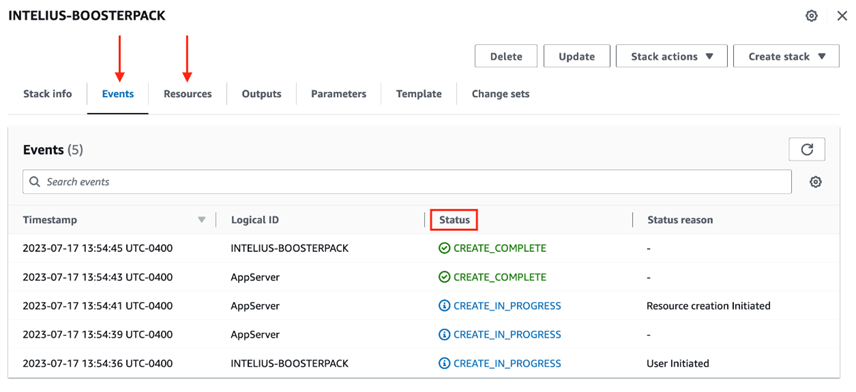
Notez l’adresse IP qui apparaît sur l’onglet Sorties de la page CloudFormation du Propulseur. Il s’agit de l’adresse IP externe de l’instance qui vient d’être créée. Vous en aurez besoin pour accéder à l’interface web de l’application ou vous connecter au serveur par le protocole SSH.
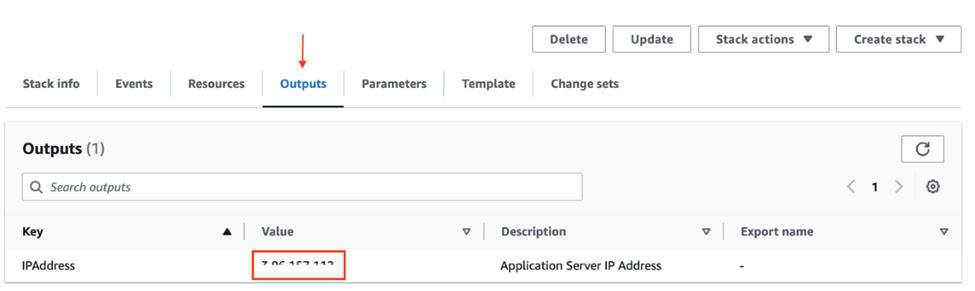
Connectez-vous au serveur de l’application à partir d’une coquille ou d’un terminal utilisant le protocole SSH avec la commande suivante :
ssh -i key_file.pem ubuntu@Public_IP
Remplacez « key_file » par la clé privée de la biclé SSH choisie sur le formulaire des paramètres de configuration et remplacez « Public_IP » par l’adresse IP de l’onglet Sorties, que vous avez précédemment notée.
Une fois la connexion avec le serveur de l’application établie, vous pourrez suivre le déploiement du script d’automatisation avec les commandes que voici :
source /etc/profile.d/boosterpack.sh
tail -f /var/log/boosterpack.log
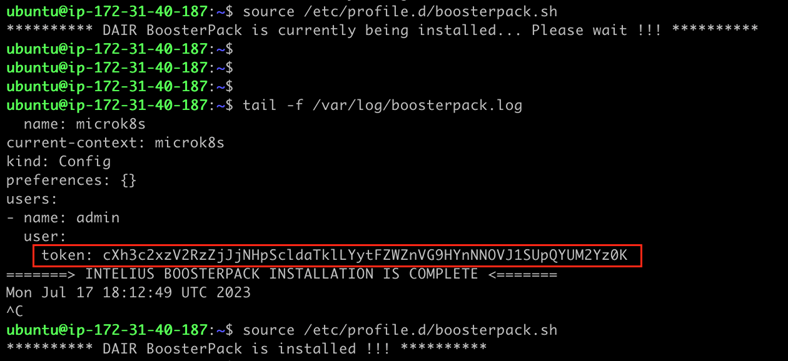
Notez le jeton indiqué à la fin du journal d’installation du Propulseur (encadré en rouge sur l’illustration qui précède). Vous en aurez besoin plus tard, quand vous vous connecterez à la console Kubernetes. Vous retrouverez aussi ce jeton sur le serveur d’application du Propulseur en exécutant la commande que voici :
microk8s config
Avant d’aller plus loin, vous devrez ajouter une règle entrante au groupe de sécurité par défaut sélectionner lors du paramétrage de CloudFormation afin que la machine locale (SOURCE) puisse accéder à la plage de ports 30000 à 32768 du TCP.
Plus sur les groupes de sécurité d’AWS
Voir plus bas la règle offerte en exemple.
Astuce : Trouvez facilement l’adresse IP de la machine en cherchant « quelle est mon adresse ip » dans Google.

Démonstration
Cette partie montre comment l’application automatise l’ingestion, le traitement, le stockage et la présentation des données boursières et des informations pertinentes analysées par le modèle préformé de prévision des sentiments.
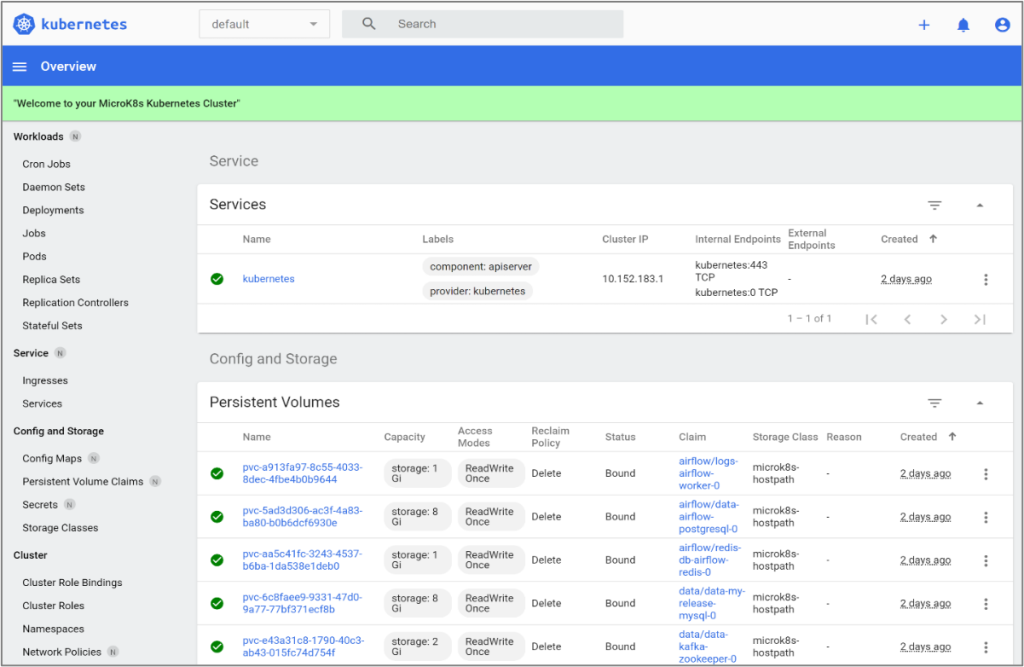
Tableau de bord Kubernetes
Les services et les applications de la Solution type s’installent sur une grappe microK8 à un nœud de Kubernetes grâce au Propulseur KAT. L’installation du tableau de bord Kubernetes suit celle des services et des applications dans la grappe, une opération qui ressemble à l’installation du Propulseur KAT. Le déploiement, script d’automatisation inclus, dure dix à quinze minutes. Les principales étapes permettant d’y accéder sont exposées plus bas. Lisez le fichier ReadMe dans la documentation KAT sur Github pour en savoir plus.
Comme on l’explique à la partie « Déploiement » de la Solution type KAT, vous devrez créer un tunnel SSH de localhost:8080, sur l’ordinateur, à localhost:80, sur le serveur d’application du Propulseur au moyen de l’IP externe de cette dernière, à partir de l’ordinateur ou avec l’outil Putty.
ssh -i key_file ubuntu@Public_IP -L 8080:localhost:80
Tel qu’indiqué précédemment, « key_file » correspond à la clé privée de la biclé SSH choisie lors du paramétrage de CloudFormation et « Public_IP » à l’adresse IP publique que vous avez notée précédemment à l’onglet Sorties de la console CloudFormation.
Allez à http://localhost:8080/dashboard/#/login et connectez-vous avec le jeton venant du serveur d’application du Propulseur.
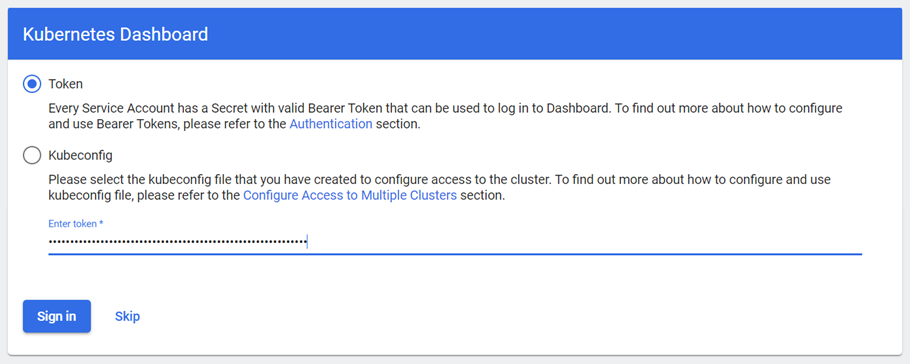
Remarque : N’oubliez pas d’exécuter la commande SSH avec l’argument de tunnelisation avant de vous connecter au tableau de bord Kubernetes avec le jeton. Consultez la documentation sur Kubernetes pour connaître les fonctionnalités du tableau de bord. Si la connexion est établie correctement, l’écran affichera ce qui suit.
Pipelines de données dans Airflow d’Apache
L’application Airflow est l’élément le plus important de la Solution type en ce qui concerne la gestion et l’usage des pipelines de données. Le service Kubernetes qui expose l’interface utilisateur d’Airflow s’appelle « airflow-webserver ». On y accède de l’extérieur avec l’URL que voici :
http://{EXTERNAL_HOST_IP}:{NODEPORT}
PUBLIC_IP correspond à l’adresse IP publique du serveur d’application du Propulseur relevée sur l’onglet Sorties de la console CloudFormation.
La valeur de NODEPORT correspond à un nombre aléatoire entre 30000 et 32768.
Pour l’obtenir :
1. ouvrez le tableau de bord Kubernetes;
2. sélectionnez Airflow dans la boîte « combo », au sommet de la page (parcourez la liste pour le trouver).
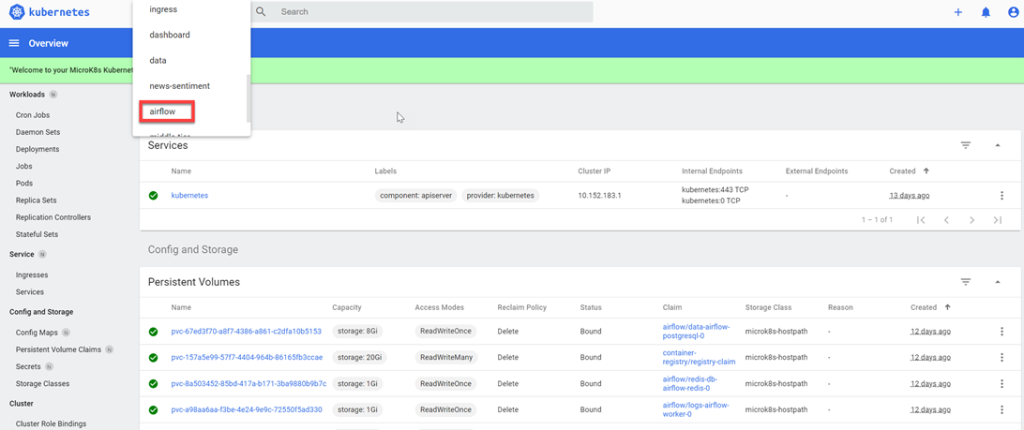
3. Sélectionnez Services dans le menu à gauche et trouvez airflow-webserver dans la liste. Le numéro du port du deuxième « Internal Endpoint » correspond à la valeur de NODEPORT que vous devez remplacer dans l’URL.
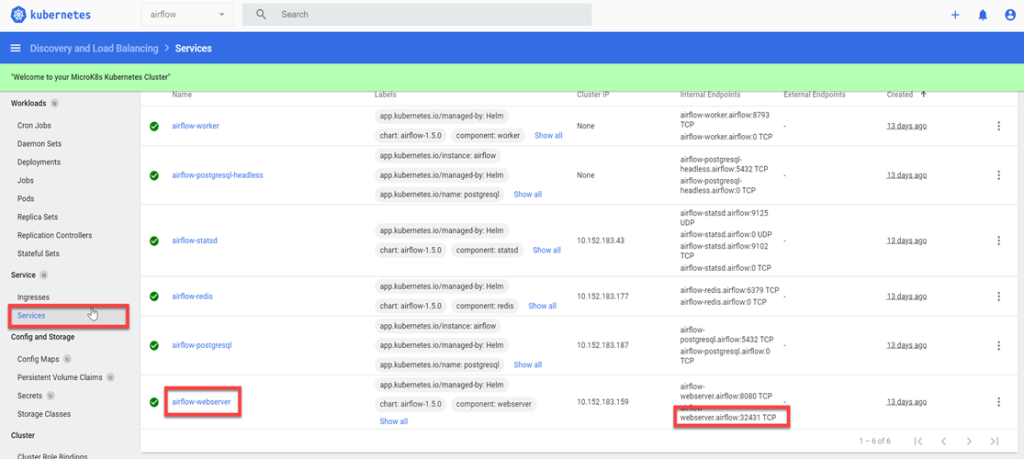
4. Allez à l’URL de vos instances (à savoir, http://3.97.56.244:32431/) et ouvrez une séance avec les identifiants par défaut que voici :
- nom d’utilisateur : admin
- mot de passe : admin
Indices: Nous vous suggérons fortement de modifier le mot de passe dans la partie « Admin » de l’interface lors de la première séance.
Remarque : La commande SSH ne doit être exécutée que pour le tableau de bord Kubernetes, pas pour l’interface utilisateur d’Airflow, ni les autres interfaces Web déployées par le Propulseur.
Une fois que vous vous êtes connecté à l’application Airflow, une page apparaîtra à l’écran indiquant les quatre pipelines de données fournis avec la Solution type.
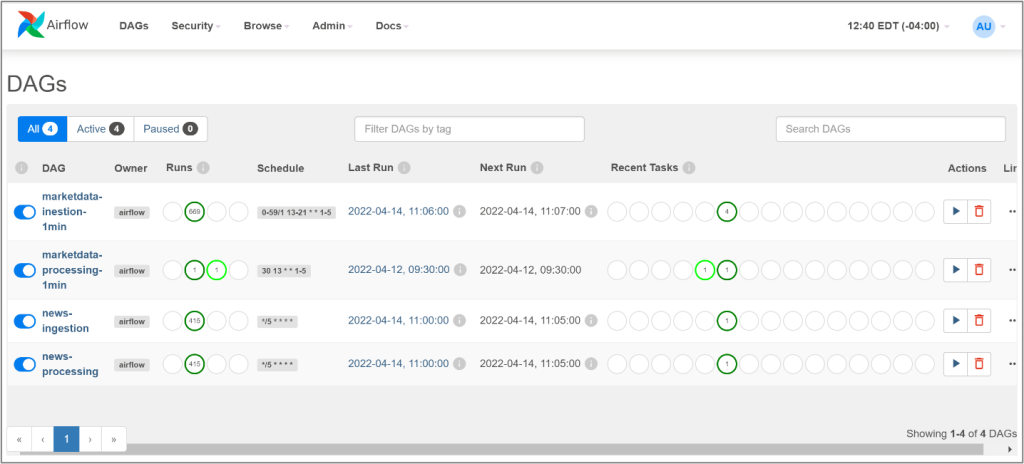
La page principale indique l’état de chaque GOA, le nombre d’exécutions et les tâches. D’autres fonctionnalités sont accessibles quand on clique sur un GOA et parcourt les pages supplémentaires. Celle-ci-dessous, par exemple, montre l’arborescence des exécutions et des tâches du GOA.
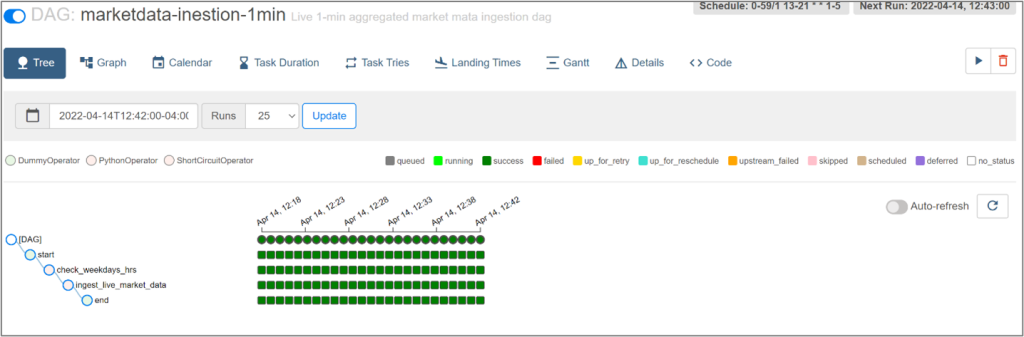
Cette interface propose plusieurs fonctionnalités permettant de gérer l’instance d’Airflow qui a été déployée. Pour un aperçu rapide de l’interface, lisez ceci, dans la documentation officielle d’Airflow.
Actualisation de la clé des API Finnhub et polygon
Les clés des API saisies lors du déploiement du Propulseur ont été sauvegardées dans les variables d’Airflow, qu’on peut gérer en allant à la page Admin > Variables de l’interface.
Pour actualiser ces clés après avoir changé l’abonnement aux deux fournisseurs de données, modifiez simplement la valeur des variables sur cette page, de la façon illustrée ci-dessous.
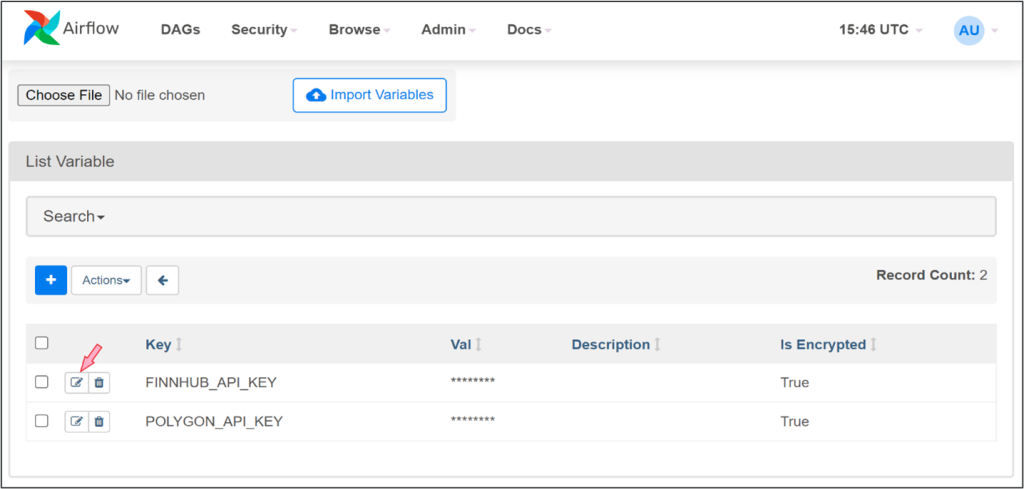
Remarque : Ne modifiez pas les clés (POLYGON_API_KEY et FINNHUB_API_KEY) tant que vous n’aurez pas changé d’abonnement ou ne serez pas passé à un service payant.
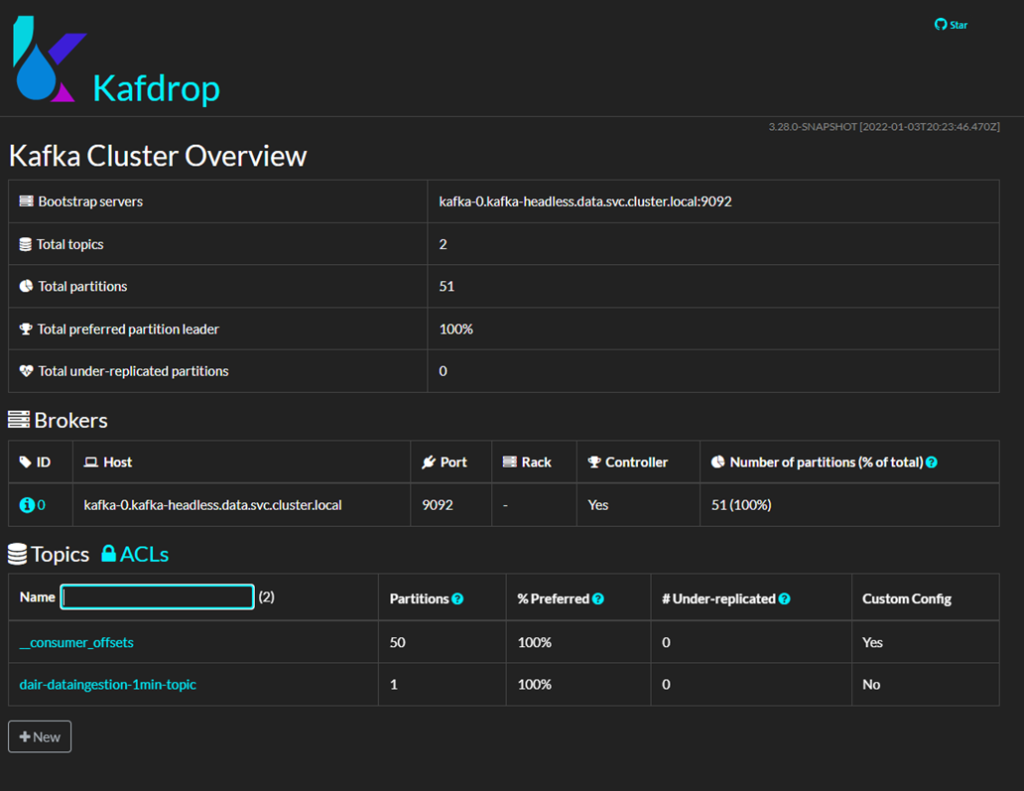
Kafdrop, une interface Web pour Kafka d’Apache
Bien qu’on puisse surveiller et gérer les serveurs Kafka de diverses manières, nous avons choisi Kafdrop comme interface Web de source ouverte. Dans cette application, le sujet « dair-dataingestion-1min-topic » de Kafka sert d’intermédiaire entre les pipelines d’ingestion et de traitement des données boursières, converties en graphiques en chandelier. Pour la surveillance et le débogage, il est possible de vérifier le moment où les messages ont été reçus et leur contenu en cliquant sur le titre de l’objet, sur la page d’accueil, puis en cliquant View Messages (voir les messages).
Kafdrop propose aussi des fonctionnalités permettant de gérer et de voir les paramètres des serveurs Kafka et des objets, ce qui peut avoir son utilité dans les cas complexes.
L’application Web de Kafdrop est disponible à l’adresse suivante :
http://{EXTERNAL_HOST_IP}:30900
MySQL, pour le stockage des données
Au déploiement de la Solution type, le système installera une instance MySQL comprenant la base de données (automated_data_pipelines) et trois tableaux dans la grappe Kubernetes.
Pour accéder à la base de données à partir de l’ordinateur, suivez les étapes du fichier readme après vous être connecté au serveur SSH de votre MV.
Si vous préférez une application comme MySQL Workbench, connectez-vous d’abord au serveur SSH de la MV et établissez un tunnel entre le port 3306 et le même port sur votre MV avec la commande que voici :
ssh [nom_utilisateur_linux]@[external_host_ip] -L 3306:localhost:3306
Une fois connecté au serveur, lancez la commande suivante :
kubectl port-forward service/my-release-mysql-headless 3306:3306 -n data
Vous devriez voir le suivi des messages, comme sur l’image ci-dessous.

Quand le suivi entre ports fonctionne, il est possible d’établir une connexion dans l’application pour gérer la base de données. Rappelez-vous de saisir ‘localhost’ comme hôte (port : 3306) et un des identifiants ci-dessous.
Privilège de super administrateur
- nom d’utilisateur : root
- mot de passe : BoosterPack202!
Utilisateur avec privilège d’accès à la base de données automated_data_pipelines
- nom d’utilisateur : adp_serviceaccount
- mot de passe : DAIRDBPass
N’oubliez pas de modifier le mot de passe « root » par défaut et le nom d’utilisateur du service pour plus de sûreté. Pour mettre fin au suivi entre ports sur l’ordinateur, enfoncez Ctrl+C.
Pour ouvrir une séance sur MySQL Workbench, créez une nouvelle connexion et vérifiez-la avec les justificatifs ci-dessus à partir de l’écran « Manage Connections ».
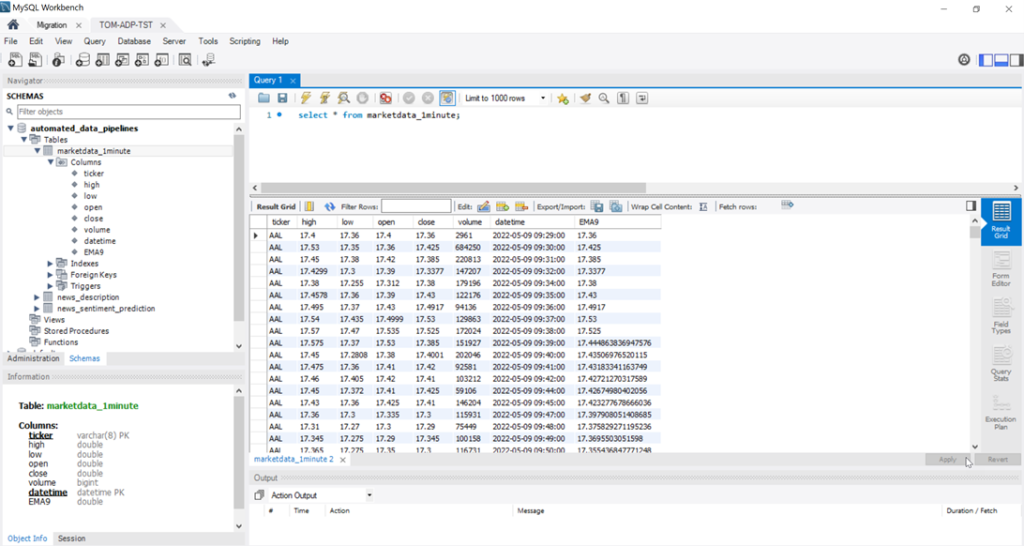
Une fois connecté à la base de données automated_data_pipelines, il est possible de la modifier et de consulter les tableaux, comme on le fait avec n’importe quel autre système de gestion de base de données.
Exemple
API du service d’analyse et du service intermédiaire
Les fonctionnalités de ces services sont visibles au moyen d’API REST, ce qui en garantit l’adaptation et la souplesse. Les appels des API ne nécessitent pas d’énoncé et puisque chaque requête est indépendante, elle doit inclure toutes les informations requises. On peut accéder à ces API – expliquées dans le Plan de vol – ou les tester avec une interface Redoc ou Swagger. L’image qui suit, par exemple, illustre l’interface Swagger de l’API qui prédit le sentiment suscité par une information boursière.

Vous trouverez des informations supplémentaires sur chacune des trois API ci-dessous.
API de prévision des sentiments suscités par les informations boursières
Indique l’émotion que devrait engendrer une information boursière particulière.
- Comment y accéder : {HOST_IP}:30602/docs OU {HOST_IP}:30602/redoc
- Requête : GET /news/description
- Corps de la requête : (voir la documentation de Polygon.io sur l’API « Ticker News » pour certains des champs qui suivent)
- ticker : symbole du titre coté en bourse
- title : titre de l’article
- news_url : URL menant à l’article
- news_content : teneur de l’article
- summary : résumé de l’article produits par l’API de Polygon.io
- id : identifiant unique de la table news_description dans la base de données de la solution type
- datetime : date à laquelle l’information a été diffusée (format « aaaa-mm-jj HH:MM).
API de description des nouvelles
Indique et décrit le sentiment évoqué par l’information boursière.
- Comment y accéder : {HOST_IP}:30300/docs OU {HOST_IP}:30300/redoc
- Requête : GET /news/description
- Corps de la requête
- ticker : symbole du titre coté en bourse
- day : date dans le format « aaaa-mm-jj »
- limit : nombre maximum d’informations boursières restituées
- skip : nombre d’articles à écarter
API sur le cours de la bourse
Produit la cote par minute pour la date et la valeur mobilière données. Faute de date, fournit les données pour la journée en cours.
- Comment y accéder : {HOST_IP}:30300/docs OU {HOST_IP}:30300/redoc
- Requête : GET /marketData/oneMinute
- Corps de la requête
- ticker : symbole du titre coté en bourse
- date : date sous le format « aaaa-mm-jj »
Interface utilisateur de la solution type ADP
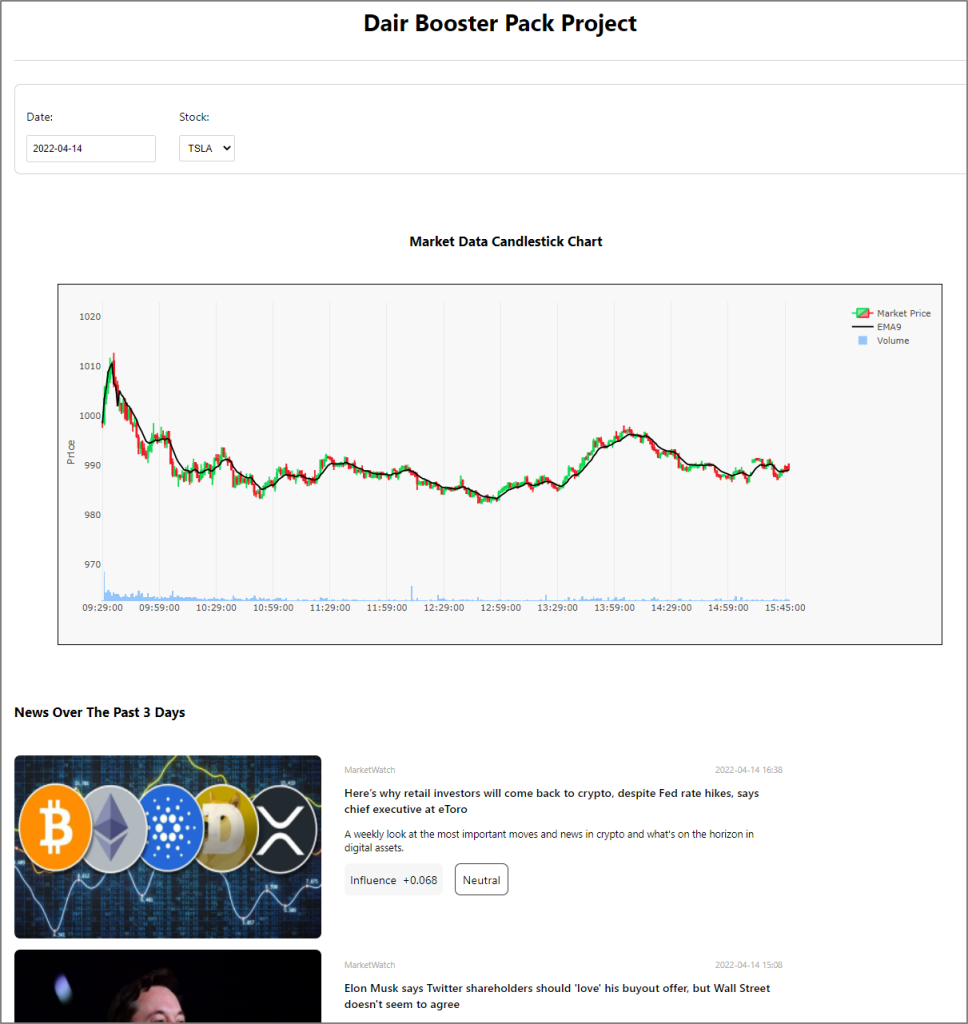
Enfin, l’ensemble se termine par les résultats, c’est-à-dire le cours des titres exprimés sous forme de graphe en chandelier et les informations qui s’y apparentent. Ces résultats sont présentés sur une simple interface Web, accessible à l’URL que voici :
{EXTERNAL_HOST_IP}:30333
La page par défaut de l’application Web est actualisée automatiquement à la date choisie, à la clôturew de la bourse. Elle présentera le graphe en chandelier du titre boursier et les actualités connexes pour les trois derniers jours. Le sentiment prévu pour chaque nouvelle correspond à une valeur numérique de son influence et à une étiquette précisant la nature du sentiment [négative, neutre, positive], après le résumé de l’article.
Remarque : Si l’application est installée pendant les heures d’activité d’une bourse des États-Unis ou en dehors, il est possible que vous ne voyiez pas de graphe ni de nouvelles avant sa réouverture, le lendemain. Dès qu’un nouveau graphe ou les informations d’un téléscripteur sont enregistrés dans la base de données, les données devraient s’afficher de la façon illustrée ci-dessous.
Clôture
Pour arrêter la solution et libérer les ressources qu’elle exploite, revenez à la page Piles de la console CloudFormation et supprimez la pile qui correspond au Propulseur.
En savoir plus sur la façon de supprimer une pile dans AWS.
Éléments à prendre en considération
Autres possibilités de déploiement
La solution type se déploie sur une grappe Kubernetes constituée d’un seul nœud. Pour accroître la performance et la disponibilité de solutions plus volumineuses, vous devrez peut-être créer d’autres instances dans le nuage, sur l’ATIR, et établir une grappe Kubernetes de plusieurs nœuds. La grappe disposera alors de ressources supplémentaires auxquelles attribuer les éléments de la solution à travers les diverses instances (les nœuds), au cas où l’une d’elles ferait défaut. Avec une telle configuration, cependant, accéder aux services par NodePort pourrait s’avérer malcommode, car les éléments de la solution et les services seront déployés sur des hôtes distincts. Dans une grappe comptant plusieurs nœuds, il serait préférable d’utiliser le contrôleur d’entrée NGINX, décrit dans le Propulseur KAT et plus loin, dans la présente partie.
Gérer une grappe Kubernetes pour de petites solutions telle celle décrite ici pourrait donner lieu à une complexité et à des frais inutiles, comparativement à une architecture de microservices similaire sur Swarm de Docker. Vous pourriez, si vous le préférez, installer les outils et les technologies de la Solution type (Airflow, Kafka, Kafdrop et MySQL) avec Docker, ce qui vous simplifiera la tâche et réduira les coûts. Pour cela toutefois, vous devrez modifier les fichiers de configuration des outils en question afin qu’ils soient compatibles avec la solution remaniée. Des changements mineurs devront être apportés au code source des services d’ingestion, de traitement et d’analyse ainsi que des services intermédiaires et frontaux.
Technologies de rechange
Les technologies et les outils que propose la Solution type ont été sélectionnés parmi des technologies de source ouverte populaires qui cohabitent bien. Vous pourriez néanmoins les remplacer par d’autres, de propriété exclusive ou de source ouverte, en fonction de votre plateforme, de vos compétences et de vos besoins en soutien technique. En voici un exemple.
| Élément | Source exclusive | Source ouverte |
| Outils d’orchestration (pour remplacer Airflow) | Azure Data Factory | Kubeflow, Luigi, Argo, etc. |
| Diffusion en continu (pour remplacer Kafka) | Azure Event Hubs | RabbitMQ, Amazon MQ, Redis |
| Stockage et gestion des données (pour remplacer MySQL) | Azure SQL | PostgreSQL, MariaDB |
La couche de présentation peut elle aussi être développée avec d’autres outils comme PowerBI ou on peut recourir à des solutions complètes comme JavaScript, Node.js, Django, Ruby, etc.
Considérations relatives aux données et aux API
Les données de la Solution type émanent principalement des sources suivantes :
- API de Finnhib.io donnant le cours boursier sous forme de graphe en chandelier;
- API de polygon.io diffusant les actualités du télescripteur sur le titre.
La Solution type recourt à l’abonnement gratuit offert par ces deux fournisseurs, mais les abonnements de ce genre ont leurs limites. Pour exploiter la Solution type à d’autres fins qu’une démonstration ou l’apprentissage, vous devrez souscrire à une autre forme d’abonnement. Le site Web de chaque fournisseur donne plus d’informations sur le coût d’un tel abonnement. Après avoir changé d’abonnement, vous devrez actualiser les variables correspondantes d’Airflow au moyen des nouveaux jetons, comme nous l’avons expliqué plus haut (actualisation de la clé des API Finnhub et Polygon).
Il est possible d’adapter la Solution type pour automatiser l’ingestion, le traitement, le stockage et la présentation de nombreuses sortes de données comme la température, les relevés venant de l’IdO, les opérations bancaires et le reste.
Si vous désirez changer la source des données, veuillez noter ce qui suit.
Pipelines Airflow
Le pipeline d’ingestion convoque les API d’après la définition des fichiers GOA donnée dans l’annexe correspondante, puis enregistre les données ingérées dans la base de données ou les envoie vers un sujet Kafka. De même, le pipeline de traitement peut être déclenché au moyen d’une annexe ou d’un message Kafka afin qu’il commence à lire et à traiter les données ingérées. Pour changer la nature ou la source des données, vous pourriez devoir modifier le code source de ces pipelines et la définition des fichiers GOA ou actualiser les paramètres généraux de ce fichier de configuration.
Table de la base de données MySQL
Si vous utilisez des données d’une autre nature ou une source de données différente, vous pourriez devoir changer l’agencement de la base de données en l’adaptant aux champs des API. Dans ce cas, vous pourriez utiliser le système de gestion de base de données de votre choix (p. ex., MySQL Workbench), tel qu’indiqué plus haut.
API du service intermédiaire
Convoquées par le service frontal, les API du service intermédiaire extraient les données des tables de la base pour que vous les visualisiez. Si vous changez la source des données et l’organisation de la base de données, vous devrez aussi modifier le code et les signatures du code source du service intermédiaire.
Service d’analyse
Si la nature des données change, vous devrez remplacer le modèle de prévision des sentiments par le vôtre. Le modèle employé par l’application de la Solution type repose sur le cadre TensorFlow. Selon le cadre qu’utilise votre modèle et le type de données, vous devrez aussi apporter des modifications au code source de ce service.
Conception du service frontal
L’interface utilisateur que propose la Solution type a été conçue à des fins de démonstration. Pour changer son aspect ou ses fonctionnalités, vous devrez modifier son code source.
Déploiement
Enfin, après avoir adapté ces services, redéployez la solution sur la plateforme Kubernetes. Lisez les fichiers ReadMe de chaque service pour savoir comment procéder (ReadMe d’Airflow, ReadMe du service de prévision des sentiments et ReadMe du service frontal).
Sécurité
La Solution type a été conçue aux fins de démonstration. Vous pouvez vous en servir comme cadre de base pour développer plus rapidement votre propre solution. La Solution type n’est pas adaptée à un environnement de production, ce qui exigerait diverses mesures de sécurité ou améliorations. Voici quelques points à prendre en considération pour rendre la solution plus sûre.
Grappe Kubernetes
Pour sécuriser la grappe, lisez les recommandations correspondantes de la Solution type KAT (partie « sécurité ») et cette partie de la documentation officielle de Kubernetes.
Pipelines d’ingestion et de traitement des données
En séparant ces deux pipelines dans l’architecture de votre système, vous rendrez celui-ci plus sûr, car seul le pipeline d’ingestion sera exposé aux données venant de l’extérieur. Bien que nous l’ayons fait dans la Solution type, les deux pipelines sont orchestrés par la même instance d’Airflow pour plus de simplicité et une plus grande économie de moyens. Pour renforcer la sécurité, vous pourriez utiliser des instances d’Airflow distinctes et modifier leur configuration en conséquence.
Pour les autres considérations concernant la sécurisation d’Airflow et les lignes directrices sur le déploiement dans un environnement de production, veuillez lire la partie « Pratiques exemplaires » du Plan de vol.
Mots de passe
Plusieurs points doivent être pris en considération à cet égard afin de renforcer la sécurité.
- Nous avons établi des mots de passe par défaut pour plusieurs outils et applications de la Solution type, notamment Airflow et MySQL. Changez-les toujours en privilégiant des mots de passe robustes.
- Quelques services de la Solution type ne sont pas protégés par mot de passe (service d’analyse et service intermédiaire). Lisez ce document officiel pour savoir comment sécuriser leur API.
- Pour plus de simplicité, la majorité des mots de passe de la Solution type sont réunis dans des fichiers de configuration en texte clair ou dans le code source.
- Nous préconisons l’usage de Secrets, de Kubernetes (où son équivalent), pour enregistrer les données sensibles comme les mots de passe et les jetons.
Images
Quelques modules de la Solution type tirent des images publiques des dépôts Docker Hub d’Intelius AI. Si vous bâtissez vos propres images après avoir modifié un service, nous vous recommandons de créer votre propre dépôt privé (clonez-le). Lisez cette documentation pour connaître les changements indispensables qui vous permettront d’extraire les images d’un répertoire privé.
Réseautique
Pour des raisons de commodité, les ports donnant accès à la plupart des services de la Solution type se trouvent dans un NodePort. Vous devez ajouter des règles au pare-feu pour autoriser l’accès à chacun. D’autres possibilités sont néanmoins envisageables, comme l’usage d’un contrôleur d’entrée ou d’un équilibreur de charge, selon vos besoins. Puisque la grappe Kubernetes créée par la Solution type repose sur le Propulseur KAT, peut-être voudrez-vous exposer ces services avec le contrôleur d’entrée NGINX, ce qui en rehaussera la souplesse ou la protection. Dans un tel cas, rappelez-vous qu’il faut ouvrir un tunnel SSH sur le port 8080 local pour avoir accès au tableau de bord de Kubernetes.
Mise à l’échelle
La mise à l’échelle de la solution ADP peut être gérée à différents niveaux et pour différents composants. Par exemple, comme on a pu le lire plus haut, on pourrait envisager une grappe Kubernetes de plusieurs nœuds afin d’ajouter plus de ressources au système, donc l’étendre. Kubernetes permet une expansion ou une contraction manuelle ou automatique de diverses manières. Ainsi, on pourra agrandir le service d’analyse ou le service intermédiaire en augmentant le nombre de modules (pods) qu’ils intègrent. Bien qu’il existe différentes façons d’y parvenir, l’illustration qui suit montre comment configurer manuellement le module de prévision des sentiments engendrés par les informations boursières avec le tableau de bord de Kubernetes.
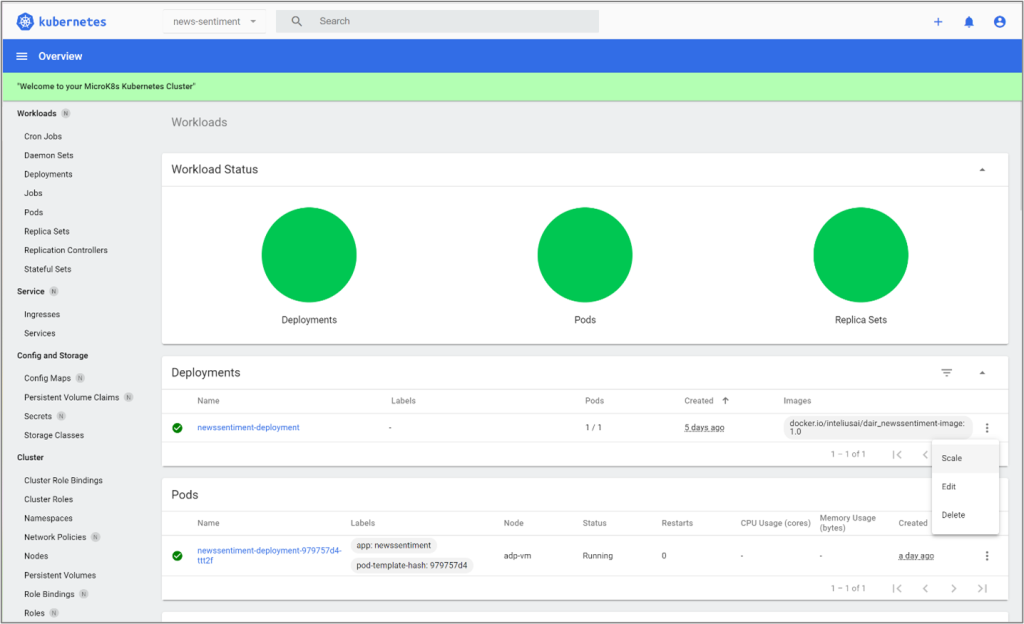
Pour en savoir plus sur les fonctionnalités de Kubernetes concernant la mise à l’échelle, lisez la documentation qui accompagne le Propulseur KAT ou cette partie de la documentation officielle de Kubernetes, qui explique en détail comment élargir horizontalement les « pods » de Kubernetes.
Le nombre d’unités de travail Airflow peut lui aussi être augmenté en vue d’une exécution des tâches prévues en parallèle. Dans la Solution type, l’instance d’Airflow utilise l’exécuteur « Celery », module qui autorise un traitement efficace et simultané de plusieurs tâches sur maintes unités de travail. Chaque unité peut être déployée sur des nœuds différents dans une grappe qui en comprend plusieurs. On peut augmenter manuellement le nombre d’unités de travail à partir du tableau de bord de Kubernetes ou accroître la valeur du paramètre « workers.replicas » dans le fichier de configuration principal d’Airflow (values.yaml) avant l’installation. Pour en savoir plus sur le fonctionnement de l’exécuteur Celery, lisez la documentation d’Airflow.
Disponibilité
Un des principaux avantages de Kubernetes est qu’on peut créer une plateforme d’une très grande disponibilité, avec peu de points de défaillance, voire aucun. Y parvenir exige toutefois ne compréhension approfondie de l’architecture de Kubernetes.
Pour en savoir plus à ce sujet, lisez les parties suivantes de la documentation officielle (en anglais) sur Kubernetes et MicroK8s :
- Création de grappes d’une grande disponibilité avec kubeadm
- Topologies accroissant la disponibilité
- Disponibilité élevée de MicroK8s
Dans la Solution type, par exemple, appliquer les recommandations concernant la création d’une grappe Kubernetes de plusieurs nœuds (ou comptant plusieurs nœuds principaux ou sites) ou permettre une mise à l’échelle horizontale automatique des « pods » en augmente la disponibilité. On pourrait aussi créer des répliques de l’ordonnanceur d’Airflow, mais la disponibilité supérieure obtenue ne garantira pas une meilleure performance.
Enfin, les recommandations du Plan de vol concernant la création d’une grappe InnoDB de MySQL pourraient accroître la disponibilité et la tolérance à une défaillance du système par une multiplication des répliques des bases de données MySQL.
Coût
Un avantage de la Solution type est que tous les outils et toutes les technologies qu’elle intègre sont de source ouverte, donc que leur licence d’exploitation est gratuite. Cependant, quand vous l’adapterez aux besoins de l’entreprise, il se peut que certains coûts s’ajoutent. Si vous songez suivre un plus grand nombre de téléscripteurs, par exemple, vous pourriez devoir changer votre abonnement à Finnhub.io ou polygon.io, ou passer à un autre fournisseur de données boursières. Peut-être préférez-vous recourir à des sources de données payantes. Des coûts s’ajouteront également si on remplace les technologies du système par des technologies analogues, mais de source exclusive.
Licence d’exploitation
Les codes et les configurations du Propulseur sont couverts par la licence d’exploitation Apache 2.0. On pourra aussi prendre connaissance des conditions associées à la licence Apache d’Airflow, à la licence Apache de Kafka et à la licence de Bitnami pour le tableau Helm de MySQL.
Codes de lancement
On trouvera le code source de la Solution type et la documentation détaillée qui l’accompagne dans ce dépôt public de GitHub.
Glossaire
Expressions revenant dans le document
| Expression | Description | Lien/source |
| Graphe orienté acyclique (GOA) | En mathématiques, et plus particulièrement dans la théorie des graphes ou en informatique, un « graphe orienté acyclique » est un graphe orienté qui ne possède pas de circuit. En d’autres termes, le graphe n’est composé que de sommets et de segments, chaque segment unissant un sommet à un autre de manière à ne former aucune boucle. | https://fr.wikipedia.org/wiki/Graphe_orient%C3%A9_acyclique |
| Pipeline de données | Moyen employé pour déplacer des données d’un endroit (la source) à un autre (un dépôt de données, par exemple). Les données sont transformées et optimisées en cours de route, de sorte qu’elles parviennent à destination dans un état qui en permet l’analyse et l’utilisation à diverses fins. | Guide Snowflake sur les pipelines de données |
| Chandelier japonais | Graphique employé en analyse technique boursière pour représenter les variations d’un cours. Il indique le cours le plus élevé d’un titre, son cours le plus bas, le cours à l’ouverture et le cours à la clôture sur une période donnée | Page d’Investopedia sur le chandelier japonais |
| Indicateur technique | Formule mathématique qui utilise le prix (et le volume) historique d’une valeur mobilière pour prédire l’évolution des cours. | Page de Wikipedia et Page d’Investopedia |
| Prévision des sentiments à partir des informations boursières | Service qui prédit l’impact d’un article sur une valeur mobilière par traitement du langage naturel (NLP) ou au moyen d’une autre technique de traitement linguistique du texte. L’impact est habituellement qualifié de positif, négatif ou neutre selon la note (influence) attribuée au sentiment. | Page de Wikipedia |
| Contrôleur d’entrée NGINX | Ingress-nginx est le contrôleur d’entrée Nginx employé par Kubernetes comme équilibreur de charge et serveur de procuration inversé. | Kubernetes Official Documentation |
| NodePort | Ce service de Kubernetes expose le service à l’adresse IP dans chaque nœud sous forme de port statique (le NodePort). On peut contacter le service NodePort de l’extérieur de la grappe avec une requête <NodeIP>:<NodePort>. | Documentation officielle de Kubernetes |